📝 Paper Summary
Conversational personalization
Agentic AI
A dialogue system acts as an interviewer to elicit detailed product feedback from users, then automatically generates a structured review and predicts a rating based on the conversation history.
Core Problem
Writing high-quality, detailed user reviews is time-consuming and labor-intensive for humans, while existing automated generation methods lack sufficient subjective details to be truly personalized.
Why it matters:
- Detailed reviews are crucial for other buyers' decision-making and provide valuable feedback for sellers to improve product quality
- Existing automated methods rely on limited inputs (e.g., just ratings or images) and struggle to incorporate the user's specific personal experiences without direct input
- Reducing the burden of writing encourages more users to share valuable feedback that might otherwise remain unwritten
Concrete Example:
A user might want to review an electric shaver but finds writing a full paragraph tedious. Without this system, they might leave a star rating only. With this system, they chat briefly about 'small hair issues', and the system generates a full review: '...well satisfied but... some times small hair from the beard gets stucks'.
Key Novelty
Interactive Interview-to-Review Generation
- Replaces the unidirectional writing process with a bidirectional interview where a dialogue agent actively asks follow-up questions to elicit specific pros/cons
- Transforms the resulting conversational history into a non-conversational review format using a generative model, rather than just summarizing it
- Decouples the rating process by predicting a score based on the generated text's sentiment, aiming to reduce subjective bias in manual rating assignment
Architecture
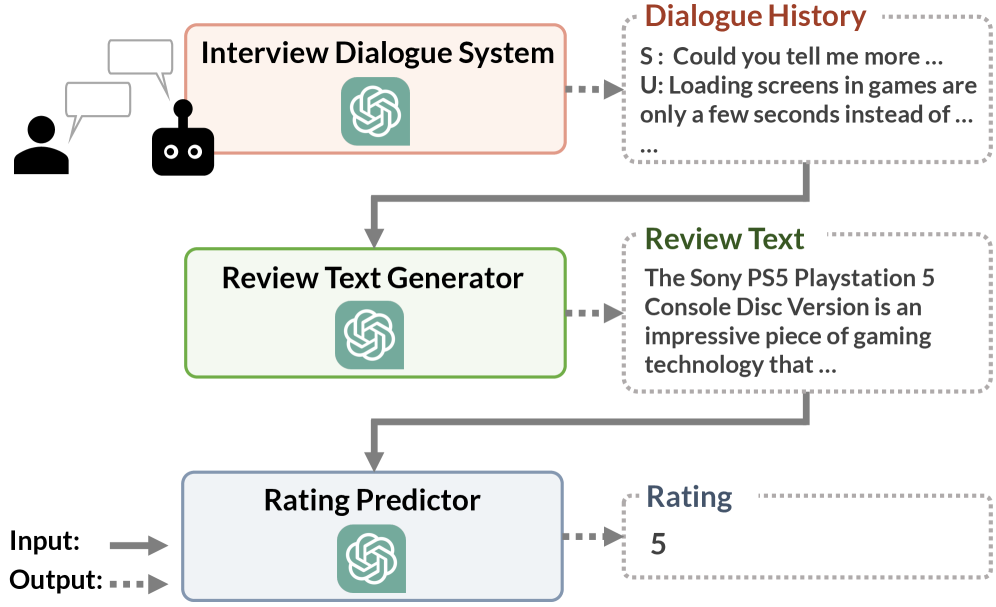
The sequential pipeline of the proposed review generation system.
Evaluation Highlights
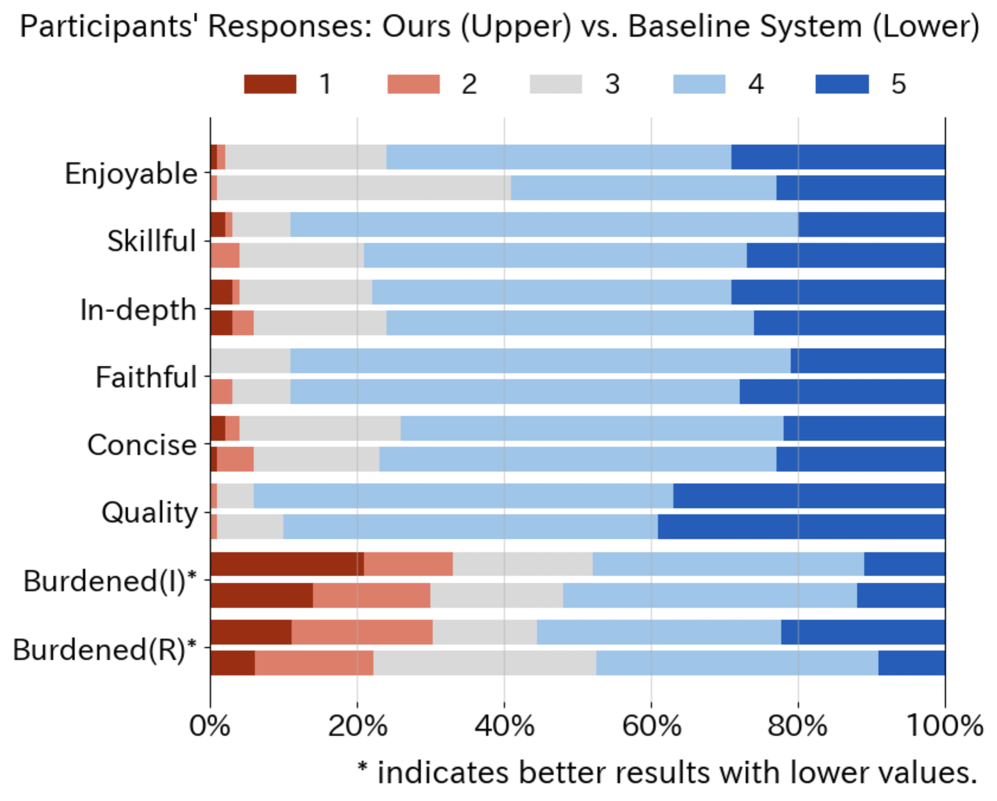
- Review readers rated system-generated reviews as more helpful than human-written reviews (55% win rate vs. 23% for human)
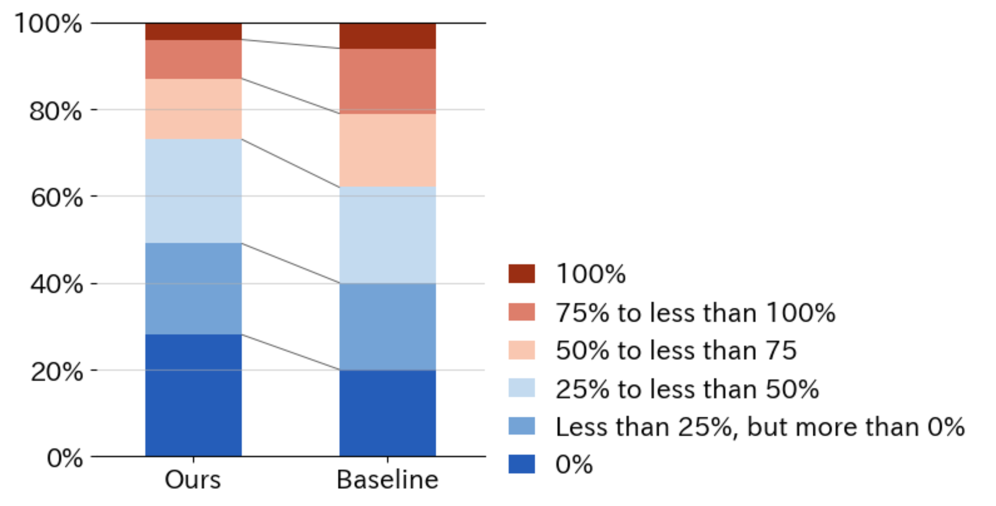
- System-generated reviews required less editing for user satisfaction compared to a baseline with fixed questions (only 27% of users needed >50% rewriting vs. 38% for baseline)
- Users rated the interaction with the interview system as significantly more 'fun' compared to a static baseline questionnaire system
Breakthrough Assessment
6/10
A novel application of LLMs for interactive content creation. While the underlying tech (GPT-4) is standard, the interview-based workflow for eliciting detailed structured data is a practical UX innovation.