📊 Experiments & Results
Evaluation Setup
Evaluation of 21 LRMs across 4 domains (Math, Programming, PCB, General Reasoning) using 896 queries
Benchmarks:
- OmniMath (Math Reasoning)
- HumanEval (Programming)
- GPQA (PCB (Science))
- Big-Bench Hard (General Reasoning)
Metrics:
- Redundancy Ratio (RR)
- Shortest Effective Path Length (L_eff)
- Average Degree (Topology)
- Isolated Node Ratio
- Statistical methodology: Stratified sampling for dataset construction; correlations observed but no formal significance tests reported
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparative analysis of Redundancy Ratios (RR) reveals extreme inefficiency in certain high-performing models and distilled variants. | ||||
| Average across tasks | Redundancy Ratio (RR) | Low (Pareto frontier) | 86.5% | High |
| Average across tasks | Redundancy Ratio (RR) | Low | 78.0% | High |
| Average across tasks | Average Degree | 1.0 | 1.75 | +0.75 |
| Average across tasks | Average Degree | 1.0 | 1.13 | +0.13 |
| Average across tasks | Token Count | 451 | 8817 | +8366 |
Experiment Figures
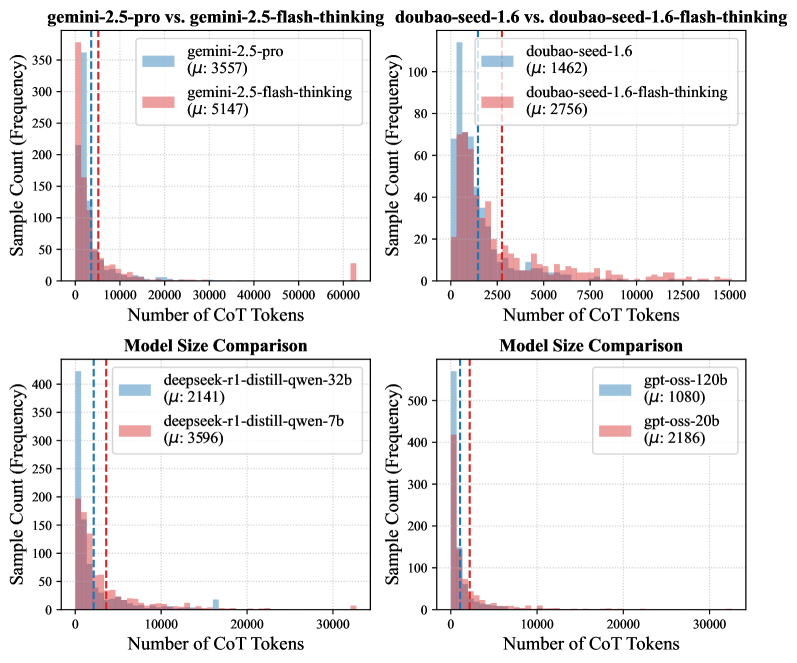
Token length distribution across models

Topological behavior (Average Degree) across difficulty levels
Main Takeaways
- Redundancy is not monolithic: DeepSeek-R1 shows 'Cyclic Complexity' (loops), Qwen3-Max shows 'Semantic Verbosity' (loose text), and Gemini-3-Pro shows 'Local Over-Optimization' (micro-backtracking).
- Distillation transmits redundancy: Distilled models (from DeepSeek-R1) inherit high redundancy (>69% RR) but often lack the verification stability of the teacher, leading to 'Destructive Revision' where correct answers are discarded.
- Redundancy peaks mid-generation: Structural analysis shows redundancy is low at start, plateaus in the middle (stabilization/context maintenance), and peaks again just before the answer (confidence calibration).
- Test-time scaling instability: Flash/smaller models show extreme token outliers (>60k tokens), indicating broken halting mechanisms on edge cases.