📝 Paper Summary
Multi-Stage Recommender Systems (MRS)
Generative Reranking
Personalized Ranking
PSAD balances reranking quality and speed by distilling a semi-autoregressive generator into a lightweight scoring network during joint training, while using a User Profile Network for deep personalized feature interaction.
Core Problem
Generative reranking models face a conflict between high quality (slow autoregressive inference) and low latency (incoherent non-autoregressive inference), while also failing to deeply capture user-item interactions.
Why it matters:
- Autoregressive models suffer from high latency and error accumulation, making them impractical for real-time industrial systems
- Non-autoregressive models sacrifice generation coherence due to strong independence assumptions, leading to suboptimal ranking lists
- Existing personalization methods often use shallow concatenation or late interaction, missing complex user interest patterns needed for effective reranking
Concrete Example:
In a standard autoregressive setup, generating a list of 10 items requires 10 sequential inference steps, causing high latency. Conversely, a non-autoregressive model generates all 10 at once but might place two incompatible items next to each other. PSAD solves this by training a fast student scorer to mimic a semi-autoregressive teacher that understands these dependencies.
Key Novelty
Personalized Semi-Autoregressive with Online Knowledge Distillation (PSAD)
- Uses a semi-autoregressive teacher that generates items in blocks (balancing speed/coherence) to supervise a lightweight student scoring network
- Performs online distillation where teacher and student are trained simultaneously from scratch, allowing the student to learn ranking knowledge on-the-fly without a pre-trained teacher
- Introduces a User Profile Network (UPN) that uses personalized gates and adaptive position encoding to dynamically modify item representations based on user intent
Architecture
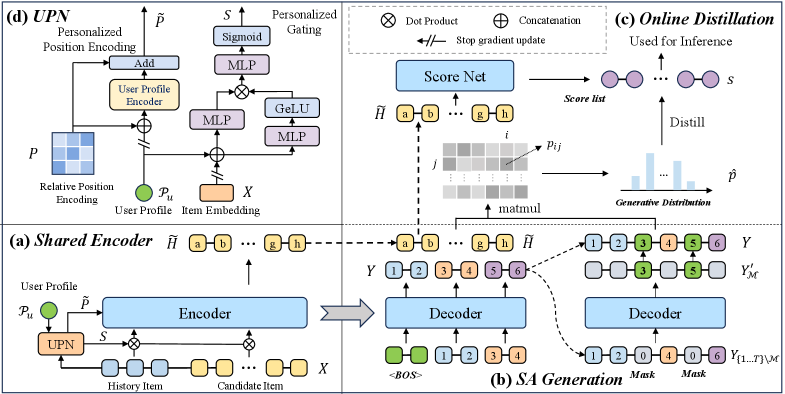
The overall architecture of PSAD, including the Shared Encoder, Semi-Autoregressive Generator (Teacher), Online Distillation process, and User Profile Network (UPN).
Breakthrough Assessment
7/10
Novel combination of semi-autoregressive generation and online distillation addresses the critical latency-accuracy trade-off in generative reranking. However, reliance on standard distillation concepts limits the theoretical breakthrough score.