📊 Experiments & Results
Evaluation Setup
Mathematical reasoning with Chain-of-Thought prompting
Benchmarks:
- MATH500 (Competition-level mathematics)
- GSM8K (Grade school math word problems)
- Danish GSM8K (Translated math reasoning (Low/Mid resource language)) [New]
Metrics:
- Accuracy
- Statistical methodology: Variability estimated using 8 generations per problem for greedy baseline
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Danish GSM8K | Accuracy relative improvement | 1.0 | 4.0 | +3.0 |
Experiment Figures
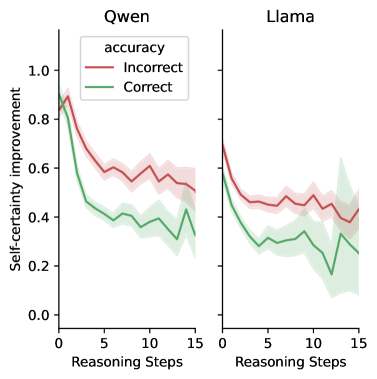
Evolution of self-certainty gains along the reasoning trajectory.
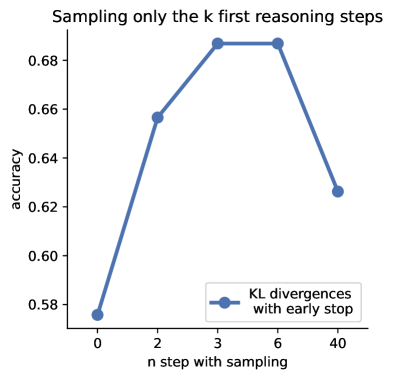
Accuracy of Qwen-3B on MATH500 when sampling is restricted to the first k steps.
Main Takeaways
- Self-certainty maximization consistently matches or exceeds Self-Consistency (Majority Voting) and Greedy decoding across Qwen and Llama model sizes.
- Method transfers robustly to Danish (low-resource setting), suggesting the uncertainty signal is language-agnostic.
- Analysis of dynamics shows correct trajectories converge to high certainty early (first ~20 steps), while incorrect ones maintain high uncertainty.
- Strategic budget allocation: Sampling is most effective in the first 1-5 steps (planning phase); sampling at later steps yields diminishing or negative returns.