📝 Paper Summary
Satellite Remote Sensing
Foundation Models
Geometric Equivariance
LEPA replaces unreliable geometric interpolation of satellite patch embeddings with a learned predictive model that accurately transforms embeddings to match user-defined areas of interest.
Core Problem
Standard interpolation methods (like bilinear interpolation) fail when applied to patch embeddings from foundation models because the embedding manifold is highly non-convex.
Why it matters:
- Users often need to align precomputed satellite embeddings to specific geographic areas of interest that do not match the fixed precomputed grid.
- Re-encoding large satellite images for every new alignment is computationally expensive and creates data-transfer bottlenecks.
- Naive interpolation of embeddings results in unrealistic representations that degrade downstream performance.
Concrete Example:
When rotating Prithvi-EO-2.0 patch embeddings by 90 degrees in latent space and reconstructing the image, the patches themselves are visible but their spatial relation is distorted. Naive bilinear interpolation of these vectors results in meaningless embeddings, yielding a Mean Reciprocal Rank (MRR) below 0.2.
Key Novelty
Learned Equivariance-Predicting Architecture (LEPA)
- Instead of averaging embedding vectors to handle geometric transformations (rescaling, rotation, translation), LEPA trains a predictor to generate the correct transformed embedding given the original context and transformation parameters.
- The model extends I-JEPA by conditioning the predictor on geometric augmentation parameters, effectively learning a 'world model' of how embeddings change under geometric shifts.
Architecture
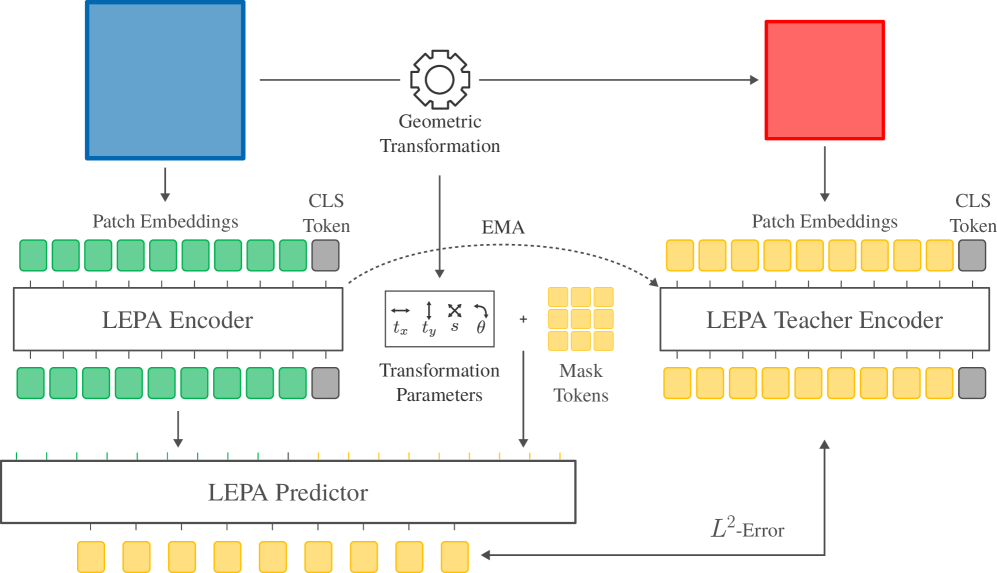
The LEPA training architecture illustrating the Context Encoder, Predictor, and Target Encoder workflow.
Evaluation Highlights
- Increases Mean Reciprocal Rank (MRR) for geometric adjustment from <0.2 (standard interpolation) to >0.8 (LEPA with fine-tuning).
- Achieves competitive semantic segmentation performance on the PANGAEA benchmark using an ImageNet-pretrained I-JEPA, outperforming HLS-trained models on the MADOS dataset.
- Demonstrates that standard interpolation methods break down for patch embeddings, while the learned predictor maintains high cosine similarity to target embeddings.
Breakthrough Assessment
7/10
Identifies a critical flaw in how embeddings are currently handled (interpolation) and provides a scalable, learned solution. The jump in MRR is substantial, though downstream segmentation gains are mixed.

