📊 Experiments & Results
Evaluation Setup
MetaDrive simulation with multi-lane roads, moderate traffic, and mixed straight/curved segments.
Benchmarks:
- MetaDrive (Autonomous Driving Control)
Metrics:
- Mean Return (Episode Reward)
- Success Rate (SR)
- Route Completion
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Ablation studies demonstrate the additive value of the proposed components (auxiliary heads + kinematic inputs). | ||||
| MetaDrive | Success Rate | 0.68 | 0.86 | +0.18 |
| MetaDrive | Mean Return | 153.05 | 171.72 | +18.67 |
| MetaDrive | Mean Return (approx) | 150 | 200 | +50 |
Experiment Figures
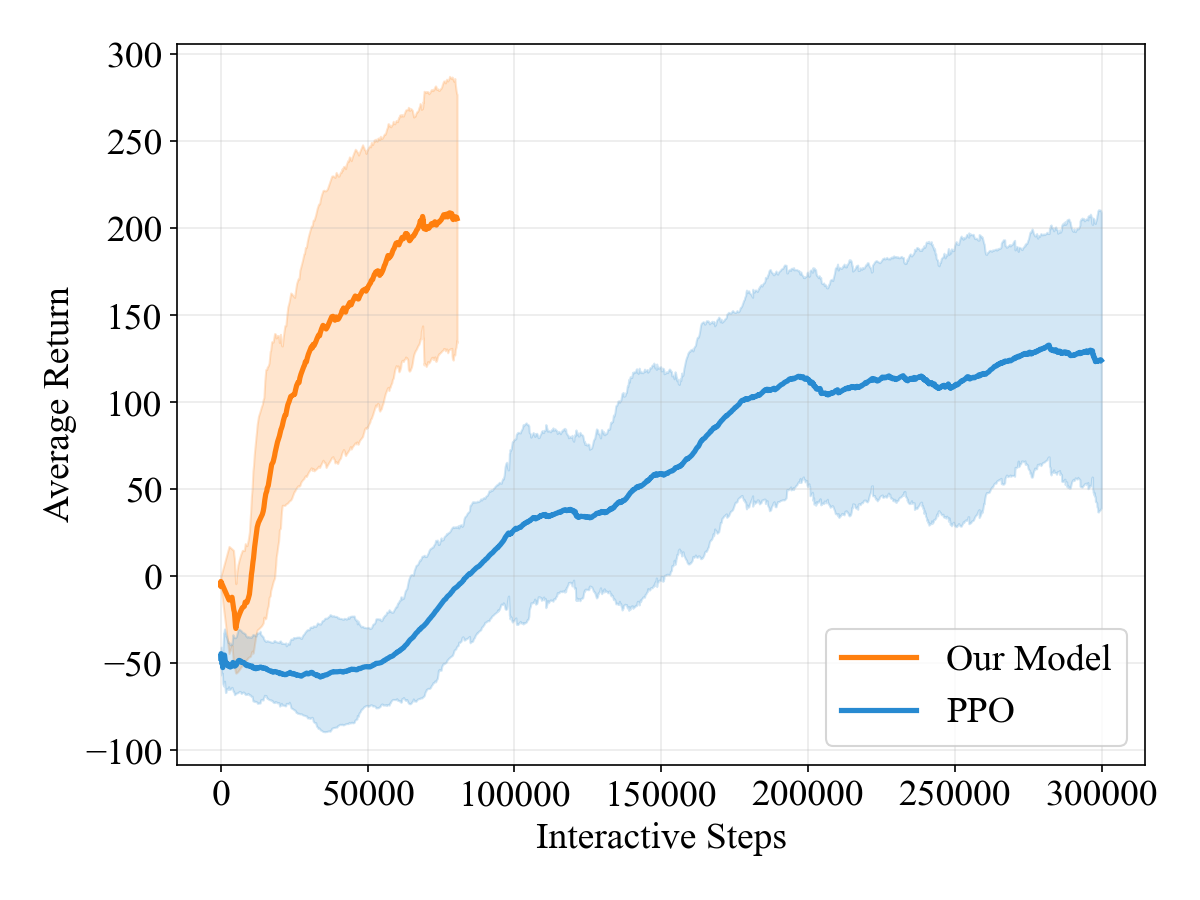
Training curves comparing Mean Return over Environment Steps for PPO vs. World Model.

Qualitative visualization of imagined trajectories (video prediction).
Main Takeaways
- Sample Efficiency: The method converges to high performance in ~80k steps, while PPO fails to match it even after 300k steps.
- Imagination Fidelity: Qualitative results show the model generates more stable and realistic future predictions (e.g., preserving lane markings and vehicle positions) compared to vision-only baselines.
- Component Synergy: Both kinematic inputs and spatial supervision heads contribute significantly; removing either leads to performance drops.
- Stability: The approach stabilizes policy optimization by grounding latent transitions in physical reality, reducing 'hallucinations' common in generative world models.