📝 Paper Summary
Representation Learning Dynamics
Implicit Bias in Optimization
Grokking and Shortcut Learning
Delayed generalization in neural networks is governed by a norm-hierarchy transition where weight decay drives a slow shift from high-norm shortcut solutions to low-norm structured features.
Core Problem
Neural networks often rely on spurious shortcuts for hundreds of epochs before discovering structured representations, but the mechanism governing when this transition occurs remains poorly understood.
Why it matters:
- Current models exploit spurious correlations (e.g., background textures) long before learning causal features, reducing robustness
- Grokking (sudden generalization long after overfitting) is observed but lacks a unified predictive theory linking it to standard learning dynamics
- Simplicity bias explains why simple features are learned first, but not the timescale of the subsequent transition to structured features
Concrete Example:
In CIFAR-10 with spurious borders, a model achieves high training accuracy by memorizing border colors (shortcut) and maintains this for many epochs before suddenly switching to classifying based on object shape (structured feature). Current theory cannot predict the timing of this switch.
Key Novelty
Norm-Hierarchy Transition (NHT) Framework
- Conceptualizes learning as a competition between multiple interpolating solutions where weight decay exerts a directed pressure from high-norm (shortcut) to low-norm (structured) representations
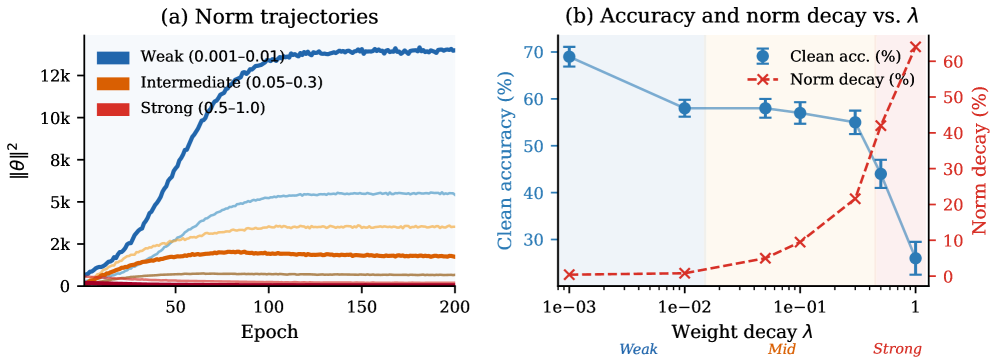
- Proposes that the delay time is logarithmically proportional to the ratio of the shortcut norm to the structured norm
- Identifies 'Clean Norm Separation' as the critical condition determining whether transition timing is predictable
Architecture
Conceptual diagram of the optimization landscape showing Shortcut Manifold (high norm) and Structured Manifold (low norm).
Evaluation Highlights
- Predicts transition delay with R^2 > 0.97 across modular arithmetic tasks, validating the logarithmic scaling law
- Demonstrates 78% → 10% clean accuracy drop (reversion to shortcuts) as shortcut strength increases in CIFAR-10, matching theoretical predictions
- Validates the framework across diverse architectures including ResNet18 with Batch Normalization, showing robustness beyond toy models
Breakthrough Assessment
9/10
Provides a unifying theoretical mechanism that connects grokking, shortcut learning, and emergent abilities. The tight theoretical bounds and multi-domain empirical validation are highly significant.