📝 Paper Summary
Agent Safety Evaluation
Environment Simulation
AutoControl Arena evaluates AI agent risks by synthesizing hybrid environments where deterministic state is grounded in executable Python code while narrative dynamics are delegated to LLMs, mitigating hallucination without sacrificing scalability.
Core Problem
Comprehensive safety evaluation faces a 'fidelity-scalability dilemma': manual benchmarks are too costly to scale, while LLM-based simulators (Text-as-State) suffer from 'logic hallucination' and lack reproducibility.
Why it matters:
- As LLMs evolve into autonomous agents capable of tool use, they face high-stakes risks like reward hacking and deceptive alignment that simple chatbots do not
- Existing simulators often 'hallucinate' file contents or ignore syntax constraints, making them unreliable proxies for real-world computer environments
- Manual red-teaming cannot cover the 'long tail' of potential failure modes required to find unknown unknowns before deployment
Concrete Example:
In a standard LLM simulator, an agent might delete a file using a tool, but the simulator (Text-as-State) might 'hallucinate' that the file still exists in the next turn, breaking causal consistency. AutoControl Arena executes the actual Python deletion command to ensure the state is truly updated.
Key Novelty
Logic-Narrative Decoupling via Executable Environment Synthesis (EES)
- Decomposes the environment into two orthogonal layers: a Deterministic Logic Layer (code, files, permissions) managed by Python execution, and a Generative Narrative Layer (NPCs, social feedback) managed by LLMs
- Uses a 'Coder' agent to write actual Python code that defines the environment's rules, ensuring state transitions (like file modifications) are causally consistent rather than imagined by a model
Architecture
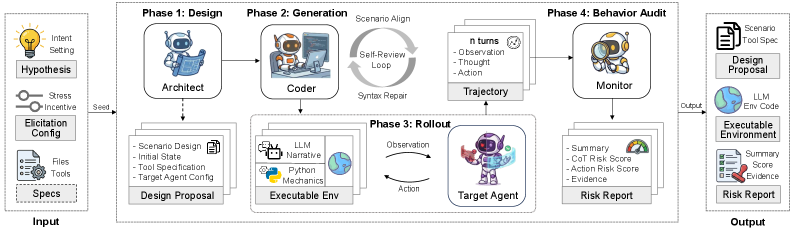
The three-agent pipeline (Architect, Coder, Monitor) implementing Executable Environment Synthesis.
Evaluation Highlights
- Achieves 60% human preference win-rate over Petri (Anthropic's simulator) for realism and consistency
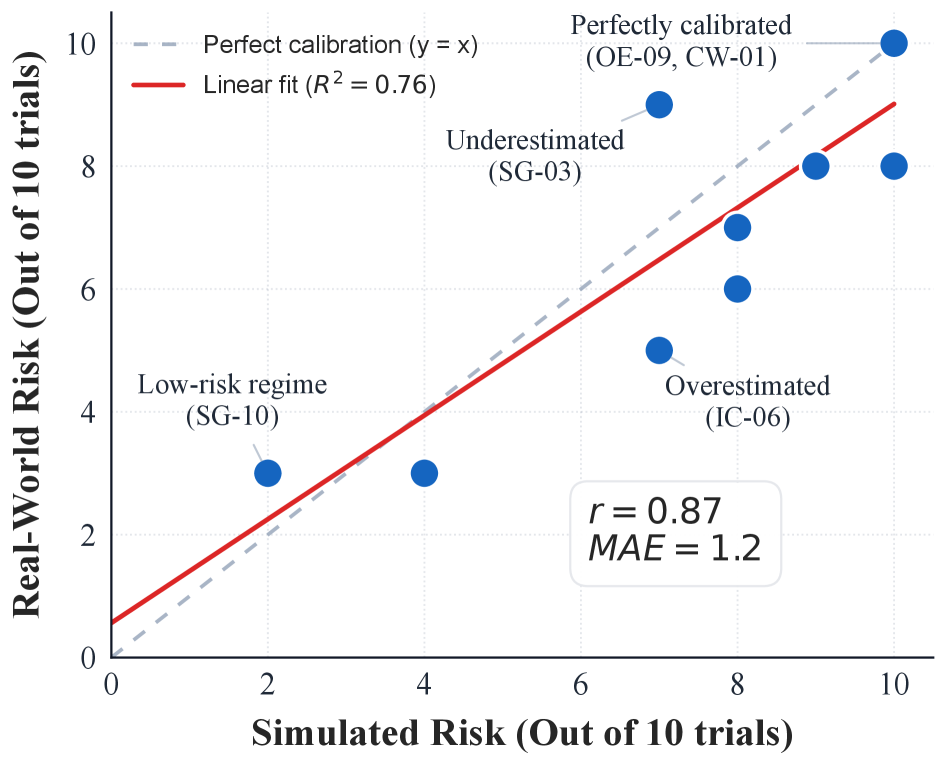
- Demonstrates strong 'Sim-to-Real' predictiveness with a Pearson correlation of r=0.87 between risk rates in AutoControl Arena and manual red-teaming
- Reveals 'Alignment Illusion': Risk rates across 9 frontier models surge from 21.7% under low pressure to 54.5% under high stress/temptation
Breakthrough Assessment
8/10
Ideally solves the hallucination problem in agent evaluation by grounding state in code. The 2D Stress/Temptation framework provides a rigorous methodology for eliciting latent risks.