📊 Experiments & Results
Evaluation Setup
Language modeling on grade-school instructional content
Benchmarks:
- Grade-school instructional corpus (Language Modeling (Next Token Prediction)) [New]
Metrics:
- Validation Loss
- Attention Pattern Specialization (Pairwise Distinctiveness)
- Attention Entropy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Ablation of mixing strategies shows that Kronecker mixing offers a favorable tradeoff between interpretability and performance cost compared to dense baselines. | ||||
| Instructional Corpus (4K vocab) | Validation Loss Increase (%) | 0 | 2.5 | +2.5 |
| Stream configuration comparisons demonstrate that freezing the token stream does not degrade performance, validating the dual-stream hypothesis. | ||||
| Instructional Corpus (8K vocab) | Validation Loss | 2.67 | 2.66 | -0.01 |
| Attention amplification experiments reveal that channelized architectures are more robust to discretization, suggesting they learn discrete algorithms. | ||||
| Instructional Corpus | Cumulative Degradation (AUC) | 99.8 | 97.2 | -2.6 |
| Stream ablation confirms functional separation: the token stream carries essential identity info while the context stream provides refinement. | ||||
| Instructional Corpus | Loss Increase (%) | 0 | 36 | +36 |
Experiment Figures
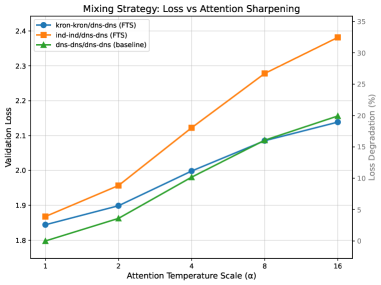
Degradation curves showing Validation Loss as a function of Attention Amplification factor $\alpha$.
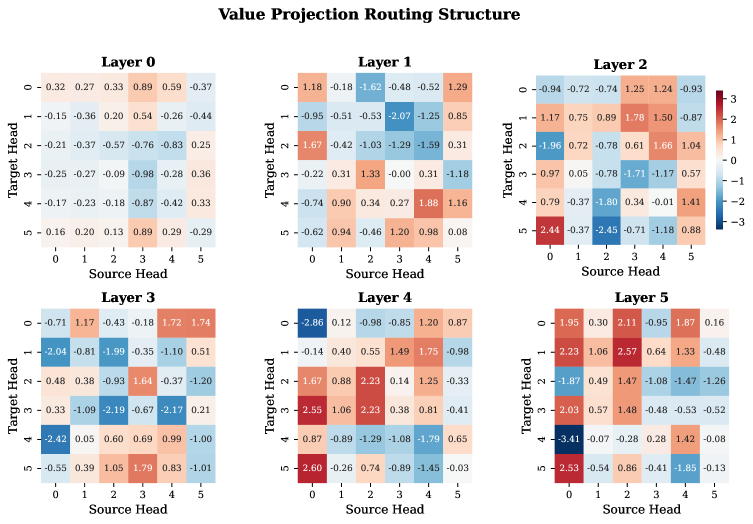
Heatmaps of the learned $H \times H$ routing matrices for Kronecker mixing layers.
Main Takeaways
- The interpretability 'tax' is predictable: 8% for fully independent heads, but only 2.5% for Kronecker mixing which preserves scalar cross-head communication.
- Models with channelized mixing degrade gracefully (linear loss growth) under attention amplification, whereas dense models accelerate in failure, suggesting channelized models learn more discrete, algorithmic operations.
- The Token Stream is the primary load-bearing component (36% loss impact if removed), while the Context Stream acts as an enhancer (9.5% impact), validating the architectural decomposition.
- Increasing head count improves specialization (distinctiveness 0.42 -> 0.85) and performance, confirming that enforcing independent channels encourages functional specialization.