📝 Paper Summary
Efficiency in Large Language Models
Diffusion Language Models
Representational Analysis
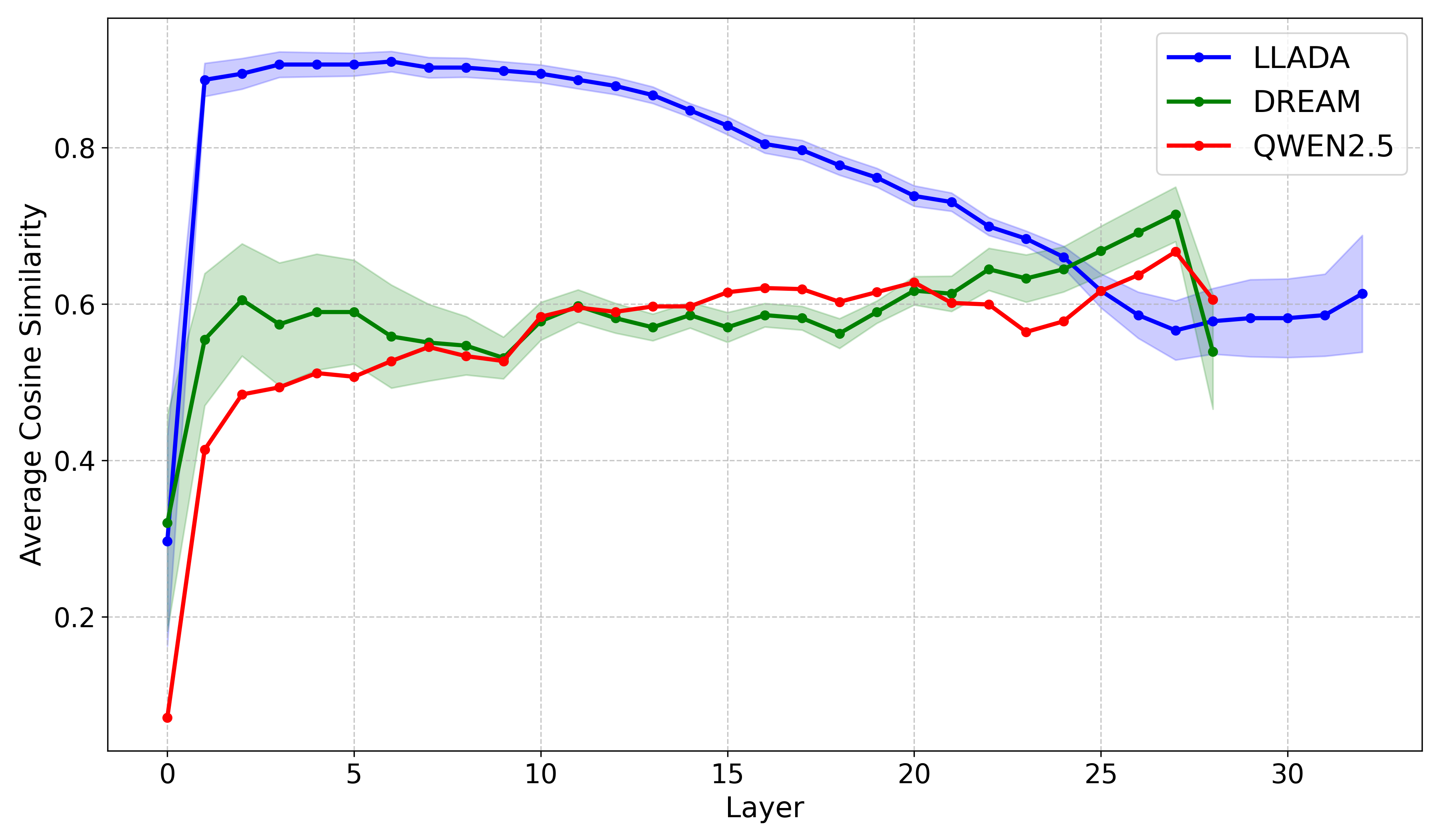
Native diffusion LLMs form hierarchical, redundant early-layer representations that allow aggressive inference-time layer skipping, whereas autoregressive models rely on brittle, incremental refinement that degrades sharply when layers are skipped.
Core Problem
Autoregressive (AR) models require executing the full network depth for every token due to tightly coupled representations, making inference computationally expensive.
Why it matters:
- Diffusion LLMs (dLLMs) are becoming competitive but their internal representational dynamics are misunderstood
- Current efficiency methods like YOCO require architectural changes or specific caching strategies, whereas identifying intrinsic redundancy could allow simpler speedups
- Understanding whether diffusion objectives actually change how models
Concrete Example:
When skipping just 2 layers in the autoregressive Qwen2.5 model, performance on GSM8K collapses (retaining only ~35-75% of baseline accuracy), whereas the diffusion model LLaDA can skip 6 layers while retaining >90% accuracy.
Key Novelty
Static, Task-Agnostic Inference-Time Layer Skipping for dLLMs
- Analyzes cosine similarity between layers to identify 'plateaus' where representations change minimally (high redundancy)
- Skips these redundant layers during inference without any architectural changes or retraining, relying on the model's residual connections to bridge the gap
- Leverages the specific 'coarse-to-fine' hierarchical structure of native diffusion models which is absent in AR models
Architecture
The logic for selecting and skipping layers during inference based on similarity thresholds.
Evaluation Highlights
- Native dLLM (LLaDA) maintains 88.2–102.1% performance retention on reasoning/coding tasks while skipping 6 layers (18.75% FLOPs reduction)
- Autoregressive Qwen2.5 degrades severely when skipping just 2 layers (34.9–75.3% retention), validating AR brittleness
- AR-initialized dLLM (Dream-7B) behaves like an AR model despite diffusion training, showing only 60.5–81.4% retention at 2-layer skips
Breakthrough Assessment
7/10
Strong empirical finding linking training objectives to representational topology. The discovery of initialization bias in Dream-7B is significant for model adaptation research. The method is simple but effective for the specific class of native dLLMs.