📝 Paper Summary
Generative Modeling
Score-Based Models
One-Step Generation
Drifting models, which move samples via kernel mean-shifts, are theoretically equivalent to minimizing a score-matching objective on kernel-smoothed distributions, bridging the gap between nonparametric transport and diffusion models.
Core Problem
Drifting models are effective one-step generators that use a mean-shift update, but their theoretical relationship to the dominant paradigm of score-based diffusion models has been unclear and heuristic.
Why it matters:
- Understanding this link legitimizes drifting models not just as a heuristic but as a mathematically grounded score-based method
- It reveals that drifting models implicitly optimize a reverse Fisher divergence (weighting errors by the model distribution), offering a complementary objective to standard diffusion's forward Fisher divergence
- Establishing this connection allows for analyzing error bounds and convergence properties using the mature tools of score-matching theory
Concrete Example:
In standard diffusion, a neural network explicitly learns a score function to denoise data. In drifting, a 'mean-shift' vector is calculated by averaging local data points weighted by a kernel. This paper shows these are effectively the same operation: the mean-shift vector *is* the score of the data smeared by the kernel.
Key Novelty
Equivalence of Kernel Mean-Shift and Smoothed Score Matching
- Demonstrates that the population mean-shift field used in drifting models is exactly proportional to the score mismatch between kernel-smoothed data and model distributions (via Tweedie's formula)
- Proves that for general radial kernels (like Laplace), the update decomposes into a preconditioned score term plus a geometry-dependent residual
- Shows that drifting optimizes a 'reverse Fisher' objective, effectively distilling the score signal nonparametrically from local neighborhoods rather than using a pre-trained teacher
Architecture
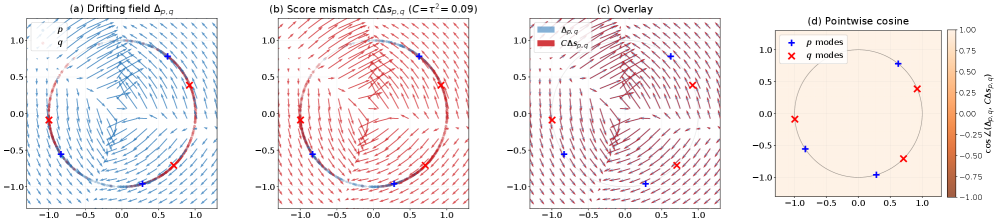
Conceptual comparison of Drifting (a) vs. Diffusion (b), and empirical validation of their equivalence (c, d)
Evaluation Highlights
- Theoretical proof: Drifting with Gaussian kernels is exactly equivalent to score matching on Gaussian-smoothed distributions
- Error bounds: For Laplace kernels, the drifting minimizer converges to the true data distribution with polynomial decay in terms of the smoothing parameter (temperature) and dimension
- Empirical validation: Visualizations confirm the mean-shift vector field aligns almost perfectly with the analytical score-mismatch field
Breakthrough Assessment
8/10
Significant theoretical contribution that unifies two distinct generative modeling families. While it doesn't propose a new SOTA architecture, it provides the rigorous mathematical foundation explaining why drifting models work.