📊 Experiments & Results
Evaluation Setup
Long-horizon interleaved generation of 40 images interleaved with text segments
Benchmarks:
- Custom Narrative Scaffolds (Interleaved Image-Text Generation) [New]
Metrics:
- Per-image quality (fidelity)
- Cross-image consistency
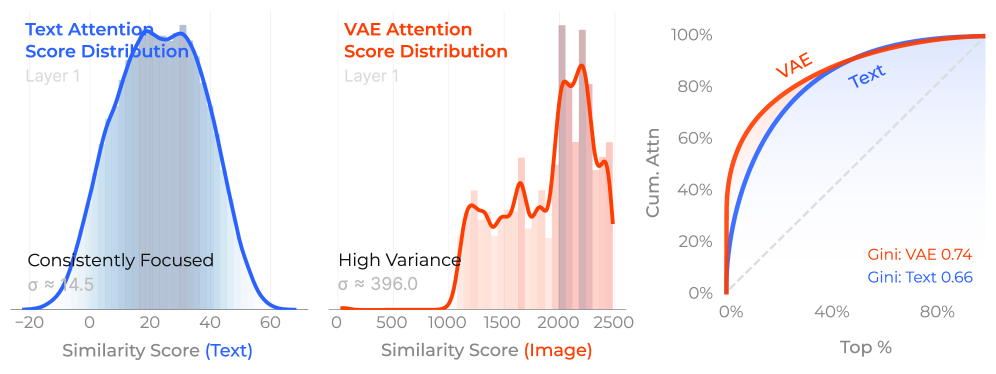
- Attention Entropy
- Key-Reference Attention Mass
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Diagnostic experiments reveal the specific thresholds and mechanisms of long-horizon collapse in unified models. | ||||
| Narrative Scaffolds (Token vs Event) | Effective Context Length (Images) | Not reported in the paper | 20 | 0 |
| Narrative Scaffolds (Token Budget) | Quality Retention at 150k tokens | 0 | 1 | Qualitative difference |
| Attention Analysis | Top-10% Attention Share | 0.10 | 0.50 | +0.40 |
Experiment Figures

Quality degradation curves across different image resolutions (creating different token counts)
Comparison of generation quality between long text-only history vs. token-matched image-heavy history
Main Takeaways
- Generation quality degrades based on the number of 'image events' (approx 20), not the raw number of tokens.
- Visual history causes 'active pollution' (injecting wrong details) whereas text history causes 'passive dilution' (vague details).
- Attention entropy increases systematically with image count, indicating the model loses focus as visual distractors accumulate.
- UniLongGen's 'active forgetting' strategy is essential for stability, suggesting future UMMs must curate rather than compress history.