📊 Experiments & Results
Evaluation Setup
Multilingual evaluation across 12 languages with focus on Russian and English, plus standard reasoning benchmarks.
Benchmarks:
- MERA (Russian language capabilities (21 diverse tasks))
- MMLU (General knowledge and reasoning (5-shot))
- GSM8K (Mathematical reasoning)
- LAMBADA (Language modeling / Next word prediction)
Metrics:
- Accuracy
- Perplexity
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Experimental validation of the 'curse of multilinguality' showing that naive mixing hurts the primary language. | ||||
| LAMBADA | Perplexity | Lower (better) | Higher (worse) | Negative impact |
| Comparative performance against state-of-the-art small models on general and Russian benchmarks. | ||||
| MMLU (MCF 5-shot) | Accuracy | 24.9 | 26.3 | +1.4 |
| MMLU (MCF 5-shot) | Accuracy | 40.2 | 45.0 | +4.8 |
| MERA | Score | Lower | Highest | Positive |
Experiment Figures
Comparison of training curves between a fixed English-heavy baseline and the dynamic two-stage model.
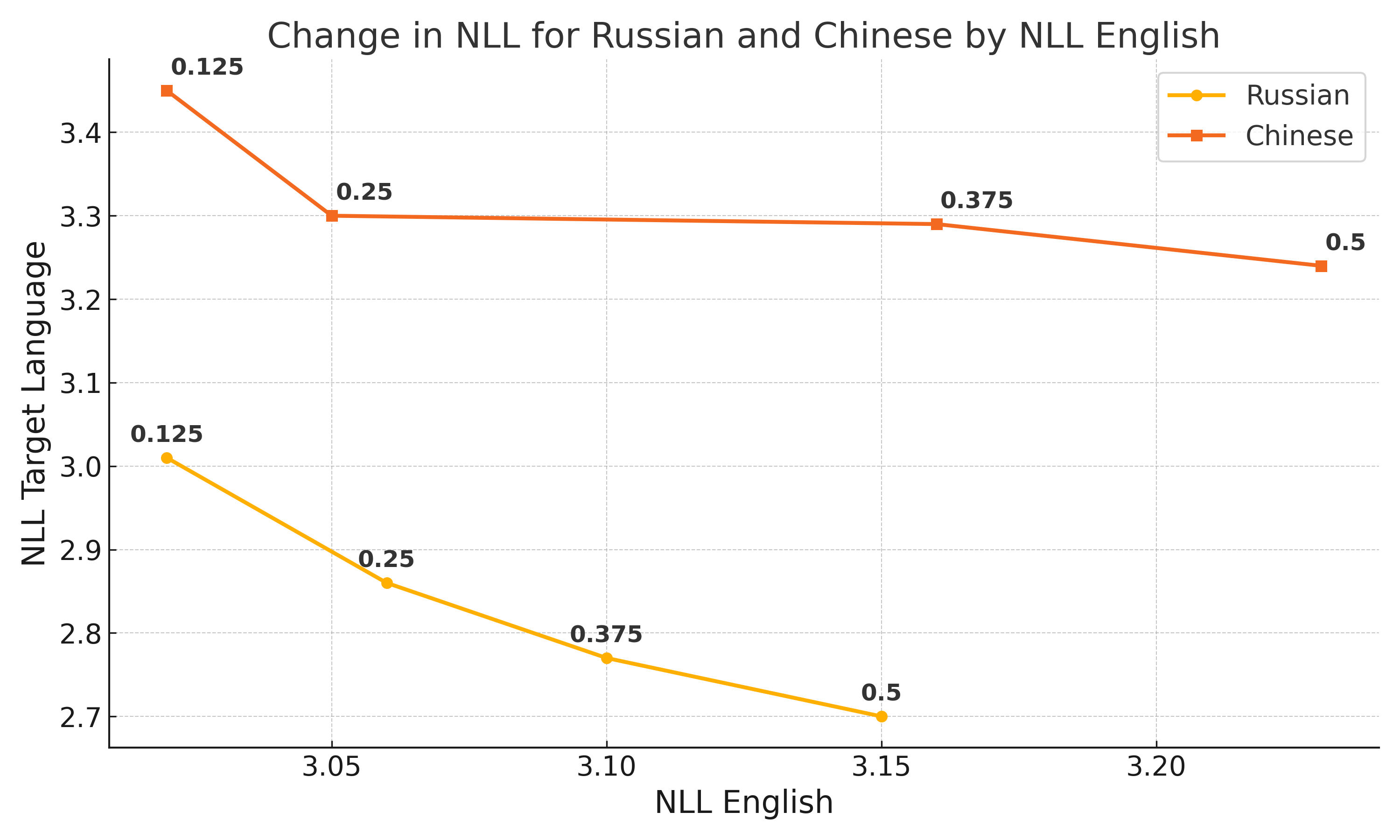
Bilingual pre-training efficiency comparison (English-Russian vs. English-Chinese).
Main Takeaways
- The 'curse of multilinguality' is real for small models: adding languages acts as noise if not managed, degrading performance even with fixed token counts for the primary language.
- Two-stage training (Balanced → English-heavy) allows a model to catch up on English performance without losing multilingual gains.
- Data quality in non-English languages is significantly lower; low-quality data actively harms the training efficiency of high-quality data.
- Small models (<2B) struggle with Multiple Choice Format (MCF) not due to lack of knowledge but due to format sensitivity; targeted post-training fixes this.