📝 Paper Summary
Agentic Recommendation
Generative Recommendation
RecPilot transforms recommender systems from passive item lists to proactive assistants by using agents to simulate user exploration and generating comprehensive, interpretable reports to support decision-making.
Core Problem
Traditional recommender systems function as passive tools that simply list items, forcing users to bear the heavy cognitive burden of exploring, clicking, reading details, and synthesizing information.
Why it matters:
- Selecting items (especially high-priced goods) remains a labor-intensive endeavor for users despite algorithmic advances
- The 'tool-based' paradigm limits user experience by assuming users must actively participate in every step of the decision process
- Existing systems facilitate access to information but fail to orchestrate the complete recommendation process to satisfy underlying intents directly
Concrete Example:
In current e-commerce platforms, to buy a product, a user must browse a list, click through multiple potential items to check specs, and mentally synthesize this data. RecPilot automates this by exploring on the user's behalf and presenting a summary report.
Key Novelty
Deep Research Paradigm for Recommendation (RecPilot)
- Replaces the conventional 'list of items' interface with a 'comprehensive report' derived from autonomous agent exploration
- Separates the recommendation process into two agents: one that simulates the tedious browsing/clicking process to find candidates, and one that synthesizes these into a structured, readable decision guide
Architecture
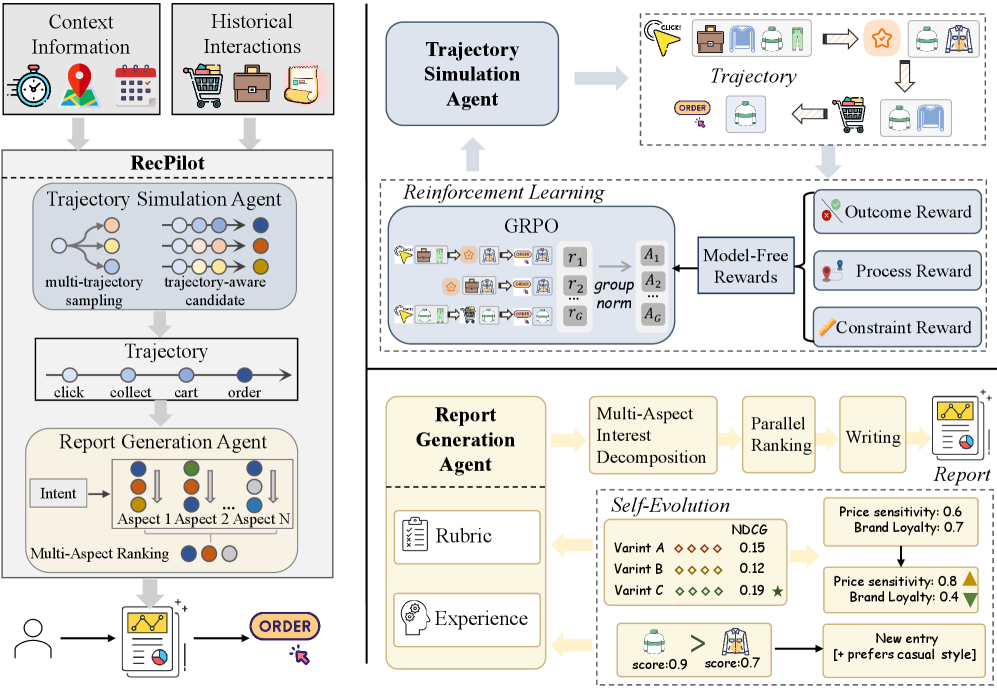
The overall architecture of RecPilot, illustrating the flow from user history to the final report via two agents.
Evaluation Highlights
- Achieves up to a 52% improvement in Recall@5 in modeling observed user behaviors compared to baselines
- Generates novel item recommendations (going beyond superficial preference matching) in 77% of cases compared with the best baseline
Breakthrough Assessment
8/10
Proposes a fundamental shift in RecSys interaction (reports vs. lists) backed by a complex multi-agent architecture. While the evaluation details in the snippet are sparse, the paradigm shift is significant.