📝 Paper Summary
Vision-Language-Action (VLA) Models
Robotic Manipulation
Continual Learning in Robotics
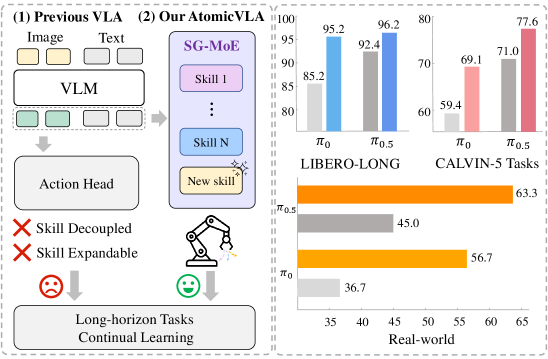
AtomicVLA unifies high-level planning and low-level control by dynamically routing atomic skill abstractions to specialized experts, enabling scalable continual learning without catastrophic forgetting.
Core Problem
Current VLA models struggle with long-horizon tasks due to poor coordination between planners and controllers, and lack scalability for continual learning because they rely on monolithic action decoders.
Why it matters:
- Decoupled planner-controller architectures suffer from lack of mutual awareness, leading to suboptimal coordination and latency issues in real-world deployment.
- Fine-tuning monolithic models for new skills is computationally expensive and causes catastrophic forgetting, interfering with previously acquired capabilities.
- Real-world robots need to acquire skills incrementally over a lifetime rather than being frozen after initial training.
Concrete Example:
In a long-horizon task like 'put the red block in the bowl then turn on the light', a standard VLA might fail to transition smoothly between 'pick' and 'turn' actions if the high-level plan becomes outdated, or forget how to 'pick' after being fine-tuned on 'turn' data.
Key Novelty
Atomic Skill-Guided Mixture-of-Experts (SG-MoE)
- Decomposes complex tasks into 'atomic skills' (e.g., pick, push, turn) via a unified Thinking-Acting process, where the model outputs either text plans or skill abstractions based on current state.
- Maps each atomic skill abstraction to a fixed embedding vector that routes execution to a dedicated, specialized expert module while retaining a shared generalist expert.
- Enables continual learning by simply adding new experts and routing branches for new skills, freezing old experts to prevent forgetting.
Architecture
The overall AtomicVLA framework, illustrating the 'Think' and 'Act' modes. It shows how visual and language inputs are processed to generate either a task plan (Think) or route to a specific expert for action generation (Act).
Evaluation Highlights
- +10% success rate improvement on LIBERO-LONG benchmark compared to the π0 baseline.
- +21% performance improvement in real-world continual learning experiments on a Franka robot compared to baselines.
- Increases average successful task execution length by 0.25 on the CALVIN benchmark (ABC-D training set).
Breakthrough Assessment
8/10
Strong contribution to VLA scalability. The atomic skill MoE design elegantly addresses both the long-horizon consistency problem and the catastrophic forgetting problem in lifelong robot learning.