📝 Paper Summary
Language Model Pretraining
Scaling Laws
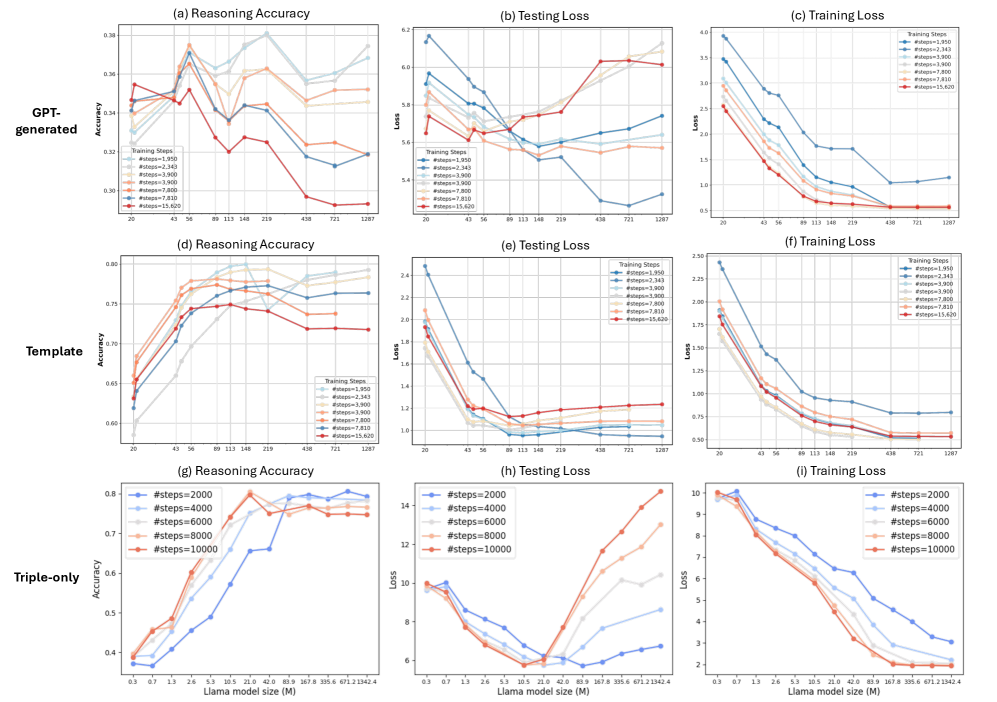
Unlike standard scaling laws, scaling model size for implicit reasoning follows a U-shaped curve where overparameterization hurts performance, governed by the information-theoretic complexity of the training data.
Core Problem
Standard scaling laws suggest larger models always improve performance, but the effect of scaling on 'implicit reasoning' (deriving new conclusions from pretraining data without explicit CoT) is poorly understood.
Why it matters:
- Current scaling laws primarily focus on perplexity or memorization, not the ability to reason over world knowledge acquired during pretraining
- Over-investing in model size might be detrimental for specific reasoning tasks if the model capacity far exceeds the complexity of the underlying knowledge structure
- Understanding reasoning capacity per parameter is crucial for efficient pretraining resource allocation
Concrete Example:
If a model learns 'A is father of B' and 'B is father of C', it should implicitly deduce 'A is grandfather of C'. The paper shows that simply increasing model size can cause the model to memorize the edges rather than learn the transitive rule, leading to worse performance on unseen valid deductions.
Key Novelty
U-shaped Reasoning Scaling Law & Graph Search Entropy
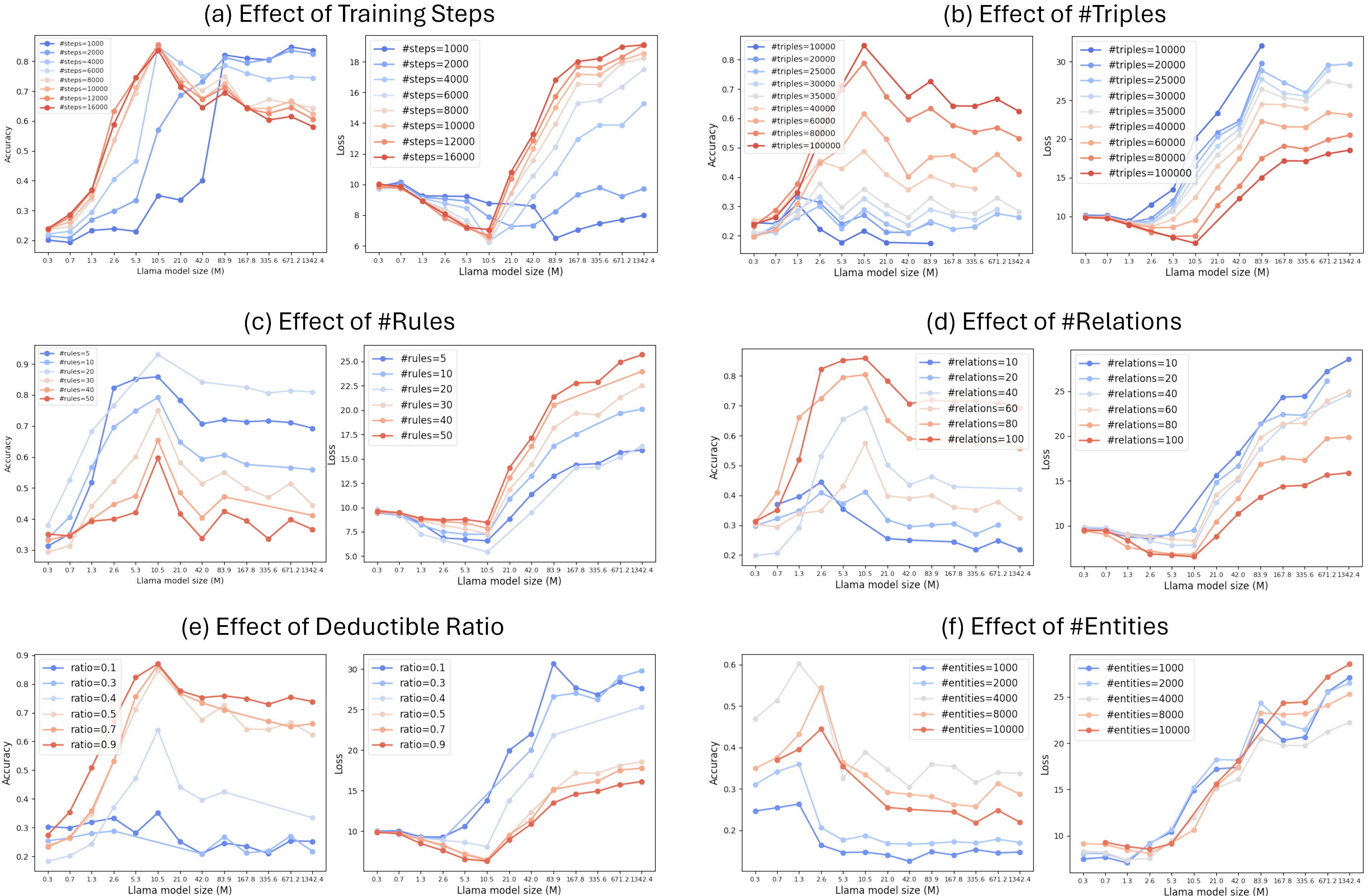
- Discovers a U-shaped loss curve for reasoning tasks: performance improves with model size up to an optimal point, then degrades due to overfitting/memorization
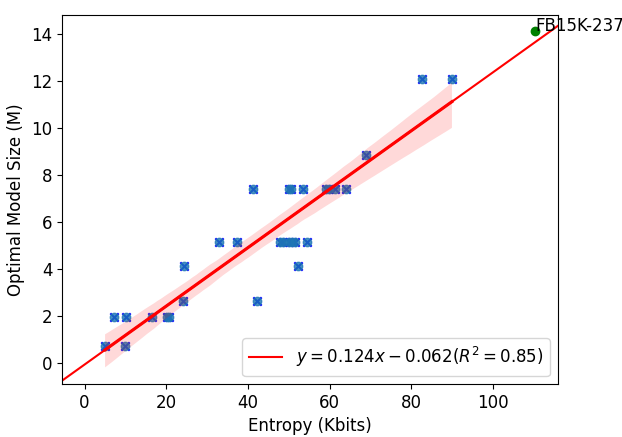
- Proposes 'Graph Search Entropy' to quantify the reasoning complexity of a knowledge graph, defined by the entropy rate of random walks over the graph
- Establishes a linear relationship between optimal model size and graph search entropy, finding LMs can reason over ~0.008 bits of information per parameter
Architecture
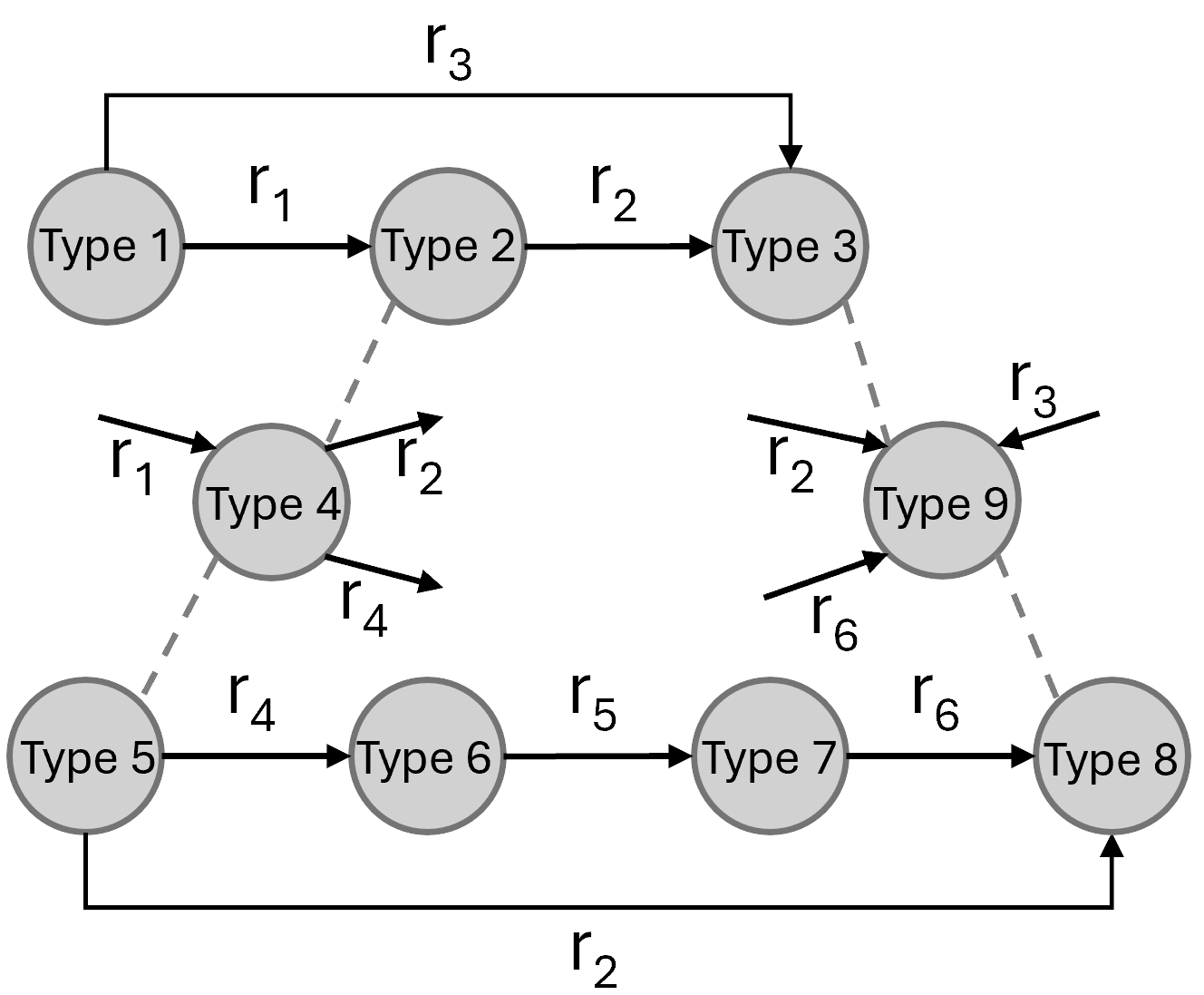
Illustration of the synthetic knowledge graph generation process, showing how node types and preferential attachment determine connectivity based on predefined logic rules.
Evaluation Highlights
- Identifies a U-shaped scaling curve where reasoning loss initially decreases but then increases as models grow beyond an optimal size (e.g., optimal size is ~1M parameters for small synthetic graphs)
- Demonstrates a strong linear correlation (R²=0.85) between the optimal model size and the proposed Graph Search Entropy metric across diverse synthetic graph configurations
- Predicts the optimal model size for the real-world FB15K-237 dataset accurately using the proposed scaling law derived from synthetic data
Breakthrough Assessment
7/10
Challenges the 'bigger is better' dogma for reasoning capabilities during pretraining and offers a novel information-theoretic metric to predict optimal size. However, findings are primarily based on synthetic/simplified environments.