📝 Paper Summary
Reinforcement Learning for Generative Models
Few-Step Diffusion Models
Text-to-Image Generation
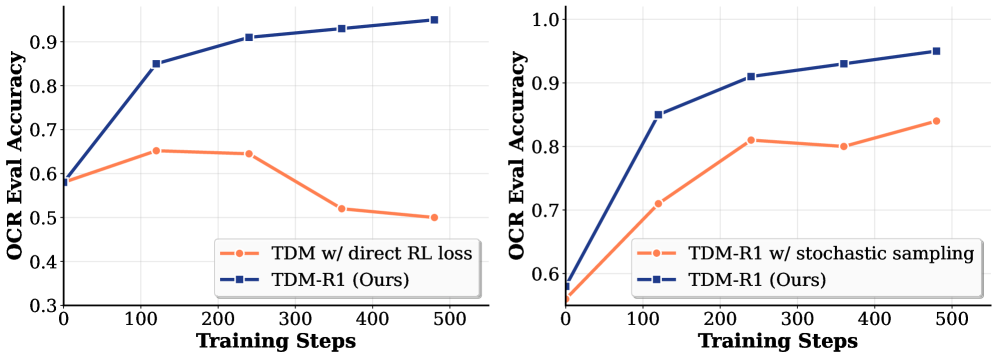
TDM-R1 enables few-step diffusion models to learn from non-differentiable rewards (like human preference or OCR) by using deterministic trajectories to accurately estimate intermediate rewards and training a dynamic surrogate reward model.
Core Problem
Existing RL methods for few-step diffusion models require differentiable rewards for backpropagation, excluding critical real-world signals like human binary preference, discrete object counts, or OCR correctness.
Why it matters:
- Reliance on differentiable rewards prevents optimization against true user intent (e.g., 'Does this image look good?') or hard constraints (e.g., 'Does the text spell exactly X?').
- Applying standard diffusion RL to few-step models fails because denoising-based RL objectives produce blurry results when steps are few.
- Assigning rewards to intermediate noisy steps is difficult, often leading to high variance or biased estimates if only the final image reward is used.
Concrete Example:
When generating an image with specific text, a standard few-step model might produce garbled letters. A non-differentiable OCR reward could correct this, but existing methods can't use it because OCR outputs aren't differentiable. TDM-R1 successfully optimizes this to produce correct text.
Key Novelty
Trajectory Distribution Matching with Surrogate Reward Learning (TDM-R1)
- Leverages the deterministic nature of Trajectory Distribution Matching (TDM) to obtain unbiased reward estimates for intermediate noisy samples, treating the final reward as a probability.
- Decouples learning into two parts: a Generator that maximizes a surrogate reward, and a Surrogate Reward model trained via group-based preference optimization to approximate the non-differentiable signal.
- Uses a dynamic reference model (EMA of the reward model) to provide stable regularization without overfitting to noisy signals or becoming too rigid.
Architecture

The iterative training loop of TDM-R1, showing the interaction between the Few-Step Generator, the Non-Differentiable Reward oracle, and the Surrogate Reward learner.
Evaluation Highlights
- Boosts GenEval benchmark performance from 61% to 92% using SD3.5-M, significantly surpassing the 80-NFE base model (63%) and GPT-4o (84%).
- Achieves superior performance with only 4 NFEs (Number of Function Evaluations) compared to expensive 80-NFE base models.
- Scales to the 6B-parameter Z-Image model, outperforming both its 100-NFE and few-step variants across in-domain and out-of-domain metrics.
Breakthrough Assessment
9/10
Significantly advances few-step generation by solving the non-differentiable reward problem. The performance jump on GenEval (beating GPT-4o with a few-step model) is remarkable and practically impactful.