📝 Paper Summary
Reinforcement Learning for Code Generation
Large Language Model Training
MicroCoder-GRPO stabilizes reinforcement learning for coding models by dynamically adjusting temperature and selectively masking truncated outputs, enabling sustained improvements in reasoning and code generation accuracy.
Core Problem
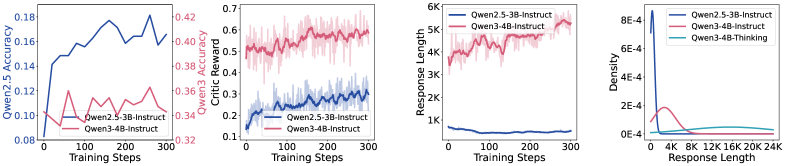
Traditional RL training methods for coding models struggle with stability and fail to improve modern models (like Qwen-3) that exhibit long output lengths and complex reasoning capabilities.
Why it matters:
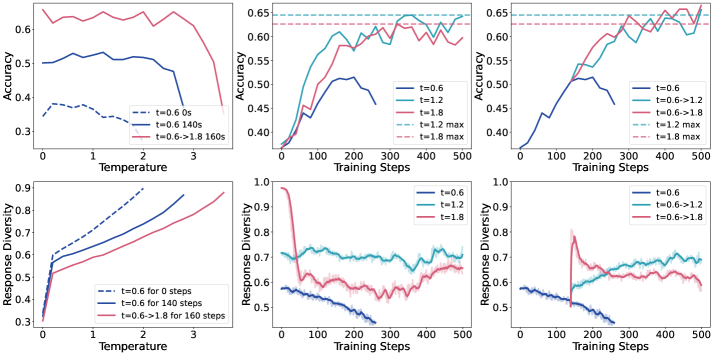
- Standard GRPO training often leads to rapid diversity collapse or length stagnation, preventing models from learning complex solution paths
- Existing datasets (DeepCoder) are too easy for modern models (Qwen-3), resulting in minimal performance gains during training
- Inaccurate evaluation metrics in current frameworks provide noisy reward signals, hindering effective policy optimization
Concrete Example:
When training Qwen-3 with standard GRPO on the DeepCoder dataset, performance stagnates because the dataset is too easy (high initial critic rewards), while the model's output length grows uncontrollably without improving accuracy. In contrast, MicroCoder-GRPO on the harder MicroCoder-Dataset sustains training improvements by managing diversity and length.
Key Novelty
MicroCoder-GRPO (Group Relative Policy Optimization with stability enhancements)
- Introduces 'conditional truncation masking' to ignore advantage scores for correct but truncated responses, preventing the model from learning to produce incomplete answers while encouraging longer reasoning chains
- Implements 'diversity-determined temperature selection' to dynamically set training temperature based on output diversity trends, preventing mode collapse
- Adopts a high clipping ratio with no KL divergence loss to allow the policy to drift significantly from the reference model, enabling the exploration of diverse, long-context solutions
Architecture
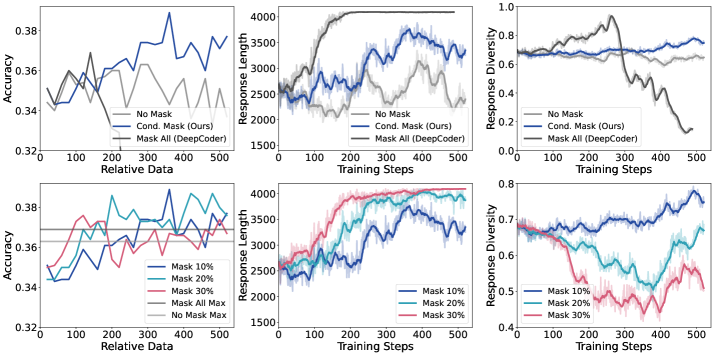
Illustration of Conditional Truncation Masking logic within the GRPO framework
Evaluation Highlights
- +17.6% relative improvement on LiveCodeBench v6 compared to strong baselines using Qwen-3 models
- Achieves 3x larger performance gains within 300 training steps using the new MicroCoder-Dataset compared to the mainstream DeepCoder dataset
- MicroCoder-Evaluator improves evaluation accuracy by approximately 25% and execution speed by 40% compared to LiveCodeBench's default evaluator
Breakthrough Assessment
8/10
Significant improvements in RL stability for coding tasks, addressing key bottlenecks like length collapse and reward noise. The release of a harder dataset and robust evaluator strengthens the contribution.