📝 Paper Summary
Code Generation
Data Curation for LLMs
Reinforcement Learning for Code
MicroCoder improves code generation models by using an LLM-based 'predict-calibrate-select' framework to filter out simplistic problems and retain only fresh, difficult competitive programming challenges for training.
Core Problem
Existing coding datasets suffer from difficulty imbalance (dominated by simple problems), lack of recency (leading to data leakage), inconsistent formats, and poor data quality (noise/missing test cases).
Why it matters:
- Training on easy problems fails to drive model improvement on complex algorithmic tasks where capabilities are most stretched
- Models often produce algorithmically correct solutions in incorrect formats (e.g., function completion vs. standard I/O) due to inconsistent training data
- Stale benchmarks allow models to memorize solutions from pre-training rather than learning to generalize to unseen problems
Concrete Example:
Web-collected problems often contain incomplete descriptions or excessive test cases (hundreds per problem) that pause training. Additionally, a mix of LeetCode-style (function completion) and OJ-style (I/O) problems without clear formatting instructions causes models to fail execution despite correct logic.
Key Novelty
Predict-Calibrate-Select Difficulty Filtering
- Uses an LLM to score problem difficulty across five dimensions (e.g., Algorithmic Thinking, Implementation) instead of relying on platform tags
- Calibrates these predicted scores against empirical pass rates from a 'thinking' model to establish ground-truth difficulty boundaries
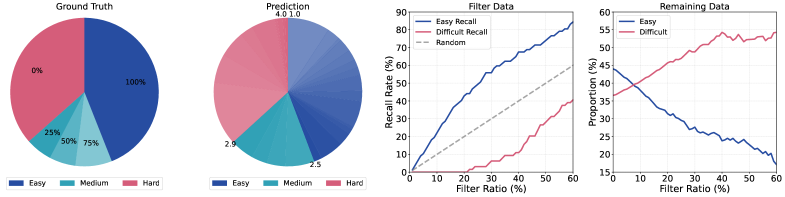
- Systematically removes simplistic problems (scoring < 2.5) to create a difficulty-dense dataset that maximizes learning efficiency
Architecture
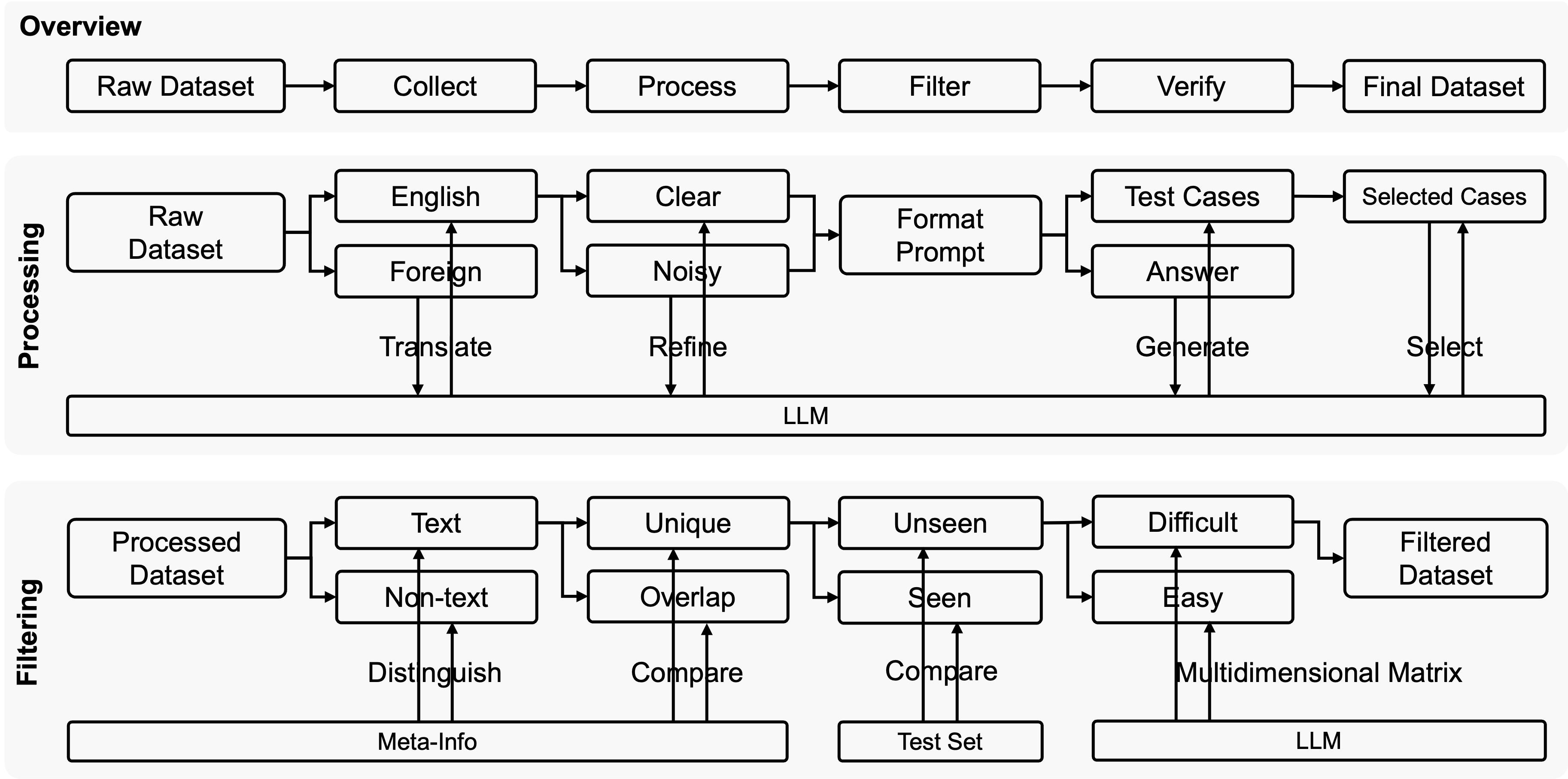
The four-stage Data Processing Framework for creating the MicroCoder dataset
Evaluation Highlights
- Achieves up to 17.2% relative gains in overall performance on medium and hard problems compared to baselines
- Delivers 3x larger performance gains within 300 training steps compared to widely-used baseline datasets of comparable size
- Reduces the ratio of easy problems in the training set from approximately 40% to under 20% via the filtering framework
Breakthrough Assessment
7/10
Presents a strong systematic framework for data difficulty scaling that yields significant efficiency gains (3x faster convergence). While the techniques (LLM-as-judge, filtering) are known, the specific application to difficulty calibration for code RL is impactful.