📝 Paper Summary
Reinforcement Learning
Value-Based Methods
Gi-TD learning stabilizes iterated TD learning by computing full gradients through stochastic targets, directly minimizing the sum of Bellman errors across a sequence of value functions.
Core Problem
Standard iterated TD learning uses semi-gradient updates where each function tracks a moving target, leading to instability and divergence because early functions in the sequence change faster than later ones.
Why it matters:
- Semi-gradient methods (like DQN) are prone to divergence in off-policy settings (e.g., Baird's counterexample), yet remain the dominant paradigm due to speed.
- Existing Gradient TD methods offer convergence guarantees but have historically suffered from slower learning speeds compared to semi-gradient approaches.
- Learning multiple Bellman iterations in parallel (iterated TD) promises speed-ups but fails if the underlying optimization doesn't account for the non-stationary nature of the targets.
Concrete Example:
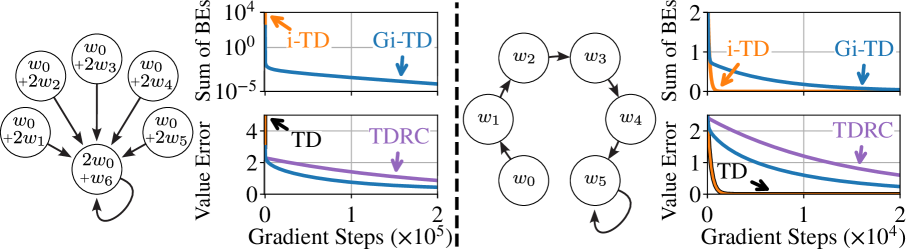
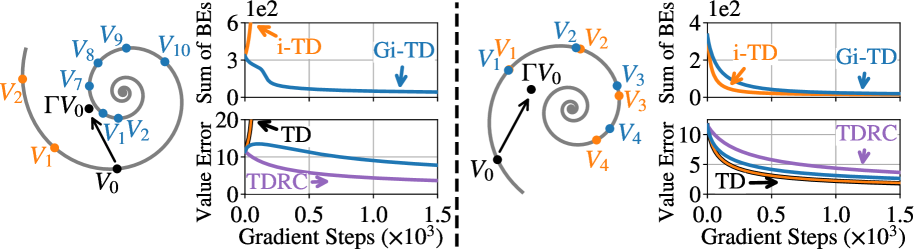
In Baird's counterexample (Star MP), standard TD and semi-gradient iterated TD (i-TD) diverge because they ignore the gradient of the target estimate. Gi-TD converges by accounting for how updating the current value function affects the target for the next function in the sequence.
Key Novelty
Gradient Iterated Temporal-Difference (Gi-TD) Learning
- Optimizes a sequence of value functions (Q0...QK) simultaneously, where each Q_k targets the Bellman update of Q_{k-1}.
- Unlike i-TD, it computes the gradient of the stochastic target terms (using a correction network similar to TDRC), ensuring the full objective—the sum of Bellman errors—is minimized directly.
- Allows future functions in the sequence to influence the learning of earlier functions, trading off early and late Bellman errors rather than solving them greedily.
Architecture
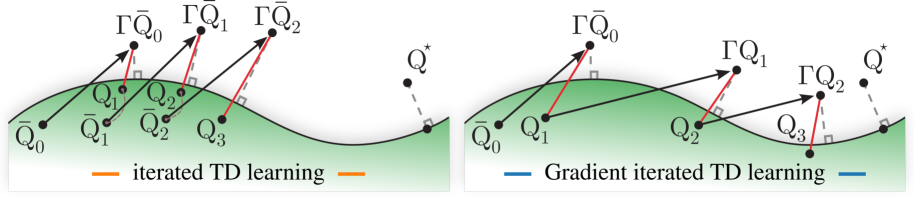
Schematic comparison of Iterated TD (i-TD) vs. Gradient Iterated TD (Gi-TD) for a sequence of functions.
Evaluation Highlights
- Converges on Baird's counterexample (Star MP) where semi-gradient methods (TD and i-TD) diverge.
- Outperforms TDRC on the Hall MP counterexample, bridging the speed gap between gradient and semi-gradient methods.
- Demonstrates competitive learning speed on the ALE (Atari) benchmark, a result not previously shown for Gradient TD-based methods.
Breakthrough Assessment
8/10
Significantly advances Gradient TD methods by making them competitive with semi-gradient methods (like DQN) on complex benchmarks (Atari) while retaining convergence properties on counterexamples.