📝 Paper Summary
Inference-time compute
Process Reward Models
Particle Filtering
This paper analyzes inference-time LLM steering through particle filtering theory, establishing bounds for Sequential Monte Carlo and proving fundamental limits on the number of particles required for myopic methods.
Core Problem
Inference-time interventions like aggregation and pruning are currently ad hoc, lacking a principled theoretical framework to explain their accuracy-cost tradeoffs or guide algorithm design.
Why it matters:
- Current methods like Best-of-N or Tree Search are empirically effective but theoretically opaque, preventing systematic improvement
- We lack understanding of how properties of the Process Reward Model (PRM), such as action-level coverage or accuracy, quantitatively impact final generation quality
- Standard particle filtering methods can fail even with perfect reward models if not carefully tuned, wasting computational resources
Concrete Example:
Even if a Process Reward Model (PRM) is perfectly accurate, standard Sequential Monte Carlo (SMC) theoretically requires roughly square-root-of-horizon particles to succeed due to interference between particles during resampling. A simple single-particle greedy method would succeed here, highlighting a pathology in standard parallel approaches.
Key Novelty
Particle Filtering Framework for LLM Inference
- Models guided generation as a sampling problem from a target distribution defined by the base model and a process reward function
- Applies Sequential Monte Carlo (SMC) theory to derive error bounds based on 'action-level coverage' (how well the base model covers high-reward tokens) and PRM accuracy
- Introduces SMC with Rejection Sampling (SMC-RS) to fix theoretical pathologies where standard SMC fails despite having good reward models
Architecture
Pseudocode for the Sequential Monte Carlo (SMC) algorithm adapted for language models
Evaluation Highlights
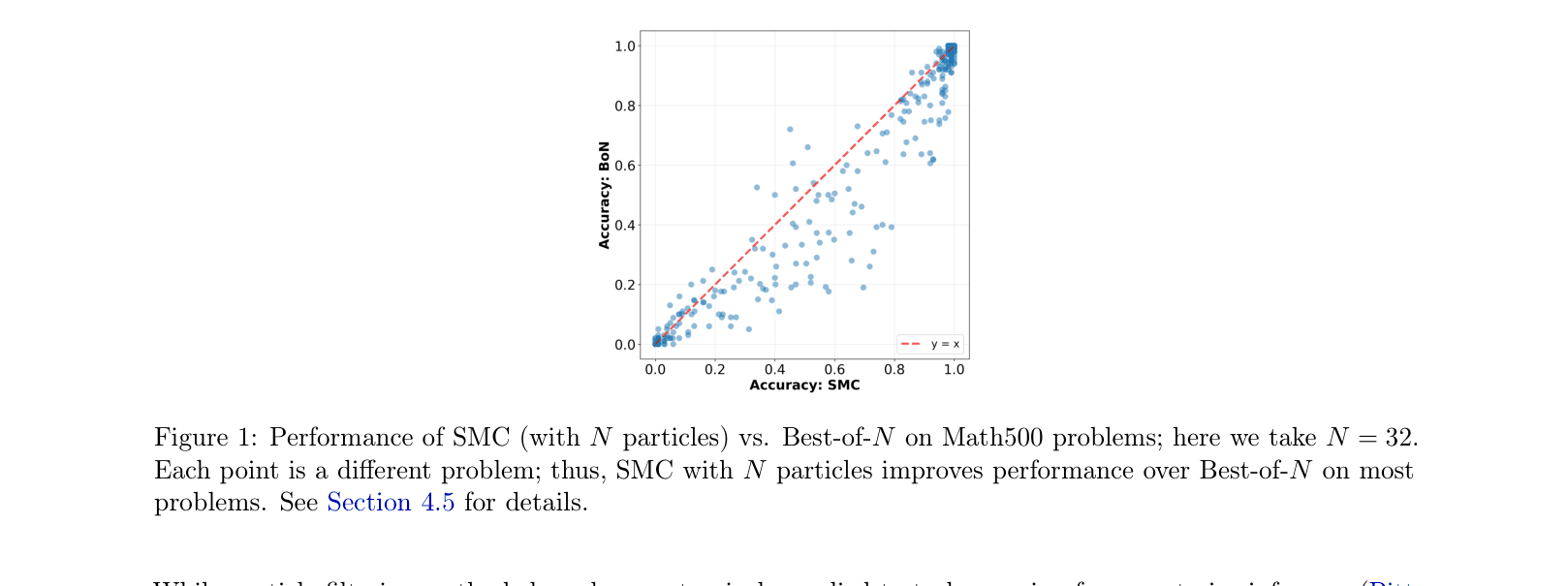
- SMC with N=32 particles consistently improves accuracy over Best-of-N (with N=32) across the vast majority of problems in the Math500 benchmark
- Theoretical proof establishes that any myopic particle filtering method requires at least logarithmic particles (in horizon H) to maintain non-trivial coverage, defining a fundamental efficiency limit
- Empirical experiments on a prompt-switching task validate that sampling error correlates strongly with theoretical predictors like action-level coverage and KL-divergence of the PRM
Breakthrough Assessment
7/10
Provides a rigorous theoretical foundation for widely used heuristic methods. While the algorithmic improvements (SMC-RS) are theoretical, the formalization of 'myopic limits' is a significant contribution to understanding inference scaling.