📝 Paper Summary
Sharpness-Aware Minimization (SAM)
Generalization in Deep Learning
XSAM improves Sharpness-Aware Minimization by explicitly estimating the direction toward the maximum loss within a specific 2D search space, rather than relying on the inaccurate gradient at the ascent point.
Core Problem
The standard SAM implementation approximates the direction toward the local maximum loss by using the gradient at a shifted ascent point, which is often inaccurate and unstable.
Why it matters:
- Applying a nonlocal gradient (computed at the ascent point) to update current parameters lacks a rigorous theoretical justification beyond rough approximation
- Multi-step SAM often performs worse than single-step SAM because the approximation quality degrades as the number of ascent steps increases
- The instability of the standard SAM approximation leads to suboptimal generalization compared to what true sharpness minimization could achieve
Concrete Example:
In a multi-step setting, the gradient at the final ascent point (g_k) might point towards a steep ascent locally, but when applied to the original parameters (theta_0), it points toward a relatively flat region, failing to identify the worst-case loss direction relative to the start.
Key Novelty
Explicit Sharpness-Aware Minimization (XSAM)
- Interprets SAM's success not as implicit bias, but because the ascent point's gradient better approximates the direction to the maximum than the local gradient
- explicitly estimates the true direction of the maximum by probing loss values within a 2D hyperplane spanned by the current gradient and the ascent vector
- Dynamically updates this directional estimate during training using a spherical interpolation factor, incurring negligible computational overhead
Architecture
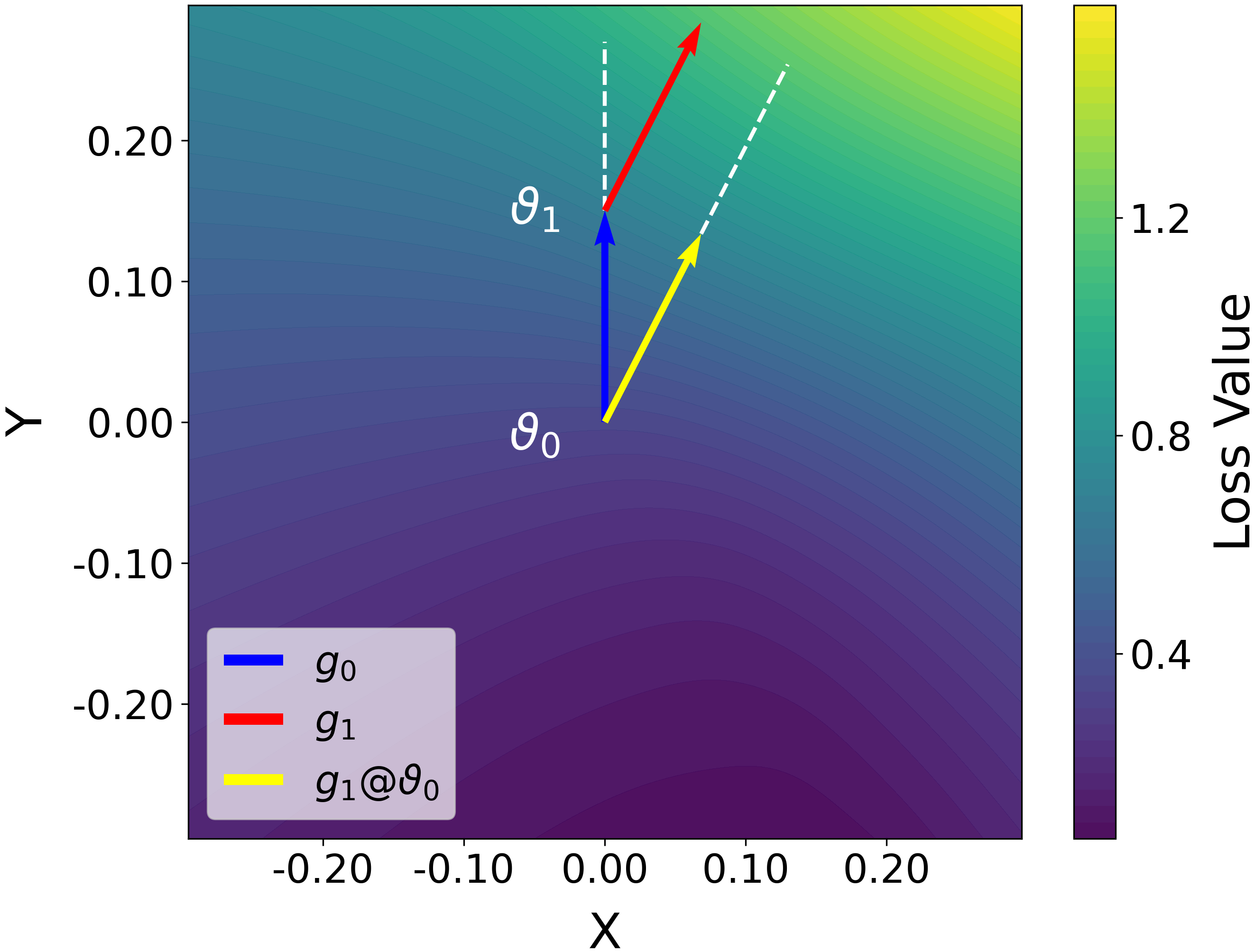
Conceptual visualization of the SAM update direction vs. the XSAM update direction on a loss surface.
Evaluation Highlights
- Outperforms SAM and variants on CIFAR-100 with ResNet-18 (error rate 16.50% vs ~17-18% for baselines)
- Consistent superiority across CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet datasets
- Achieves lower error rates than standard SAM and Adaptive SAM (ASAM) on VGG-11, ResNet-18, and DenseNet-121 architectures
Breakthrough Assessment
8/10
Provides a compelling new intuition for why SAM works and fixes a fundamental approximation flaw (the nonlocal gradient issue) with a principled, low-overhead solution.