📝 Paper Summary
Efficient Reasoning
Dynamic Compute
Agentic AI
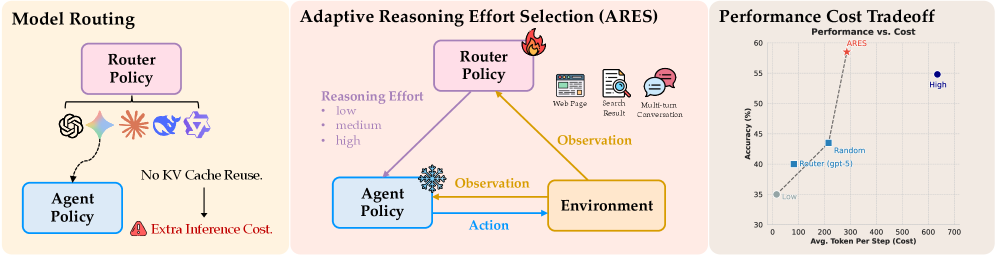
Ares reduces agent inference costs by training a lightweight router to dynamically select the minimum necessary reasoning effort (low/mid/high) for each step in a trajectory without sacrificing success.
Core Problem
Fixed reasoning strategies are inefficient: using high effort at every step is prohibitively expensive, while using low effort consistently leads to severe performance degradation (e.g., ~20% drop).
Why it matters:
- LLM agents incur massive costs during long chain-of-thought (CoT) reasoning sequences in multi-step tasks
- Existing model routing approaches (switching between different models) disrupt the KV cache, adding latency and re-computation costs
- Naive strategies like random selection or static configurations fail to balance the non-monotonic trade-off between cost and task success
Concrete Example:
In a web browsing task, an agent might need 'high' reasoning effort to navigate a complex website structure to find a specific product, but only 'low' effort to click a clearly visible target URL. A fixed high-effort policy wastes tokens on the click; a fixed low-effort policy fails the navigation.
Key Novelty
Per-step Adaptive Reasoning Effort Selection (Ares)
- Decomposes the reasoning budget problem into a sequential decision process where a lightweight router predicts the minimal sufficient 'thinking level' (high/mid/low) for the *next step only*
- Utilizes a 'verify-then-label' data synthesis pipeline that takes successful high-effort trajectories and experimentally validates the lowest effort required for each specific step to create ground-truth training data
Architecture
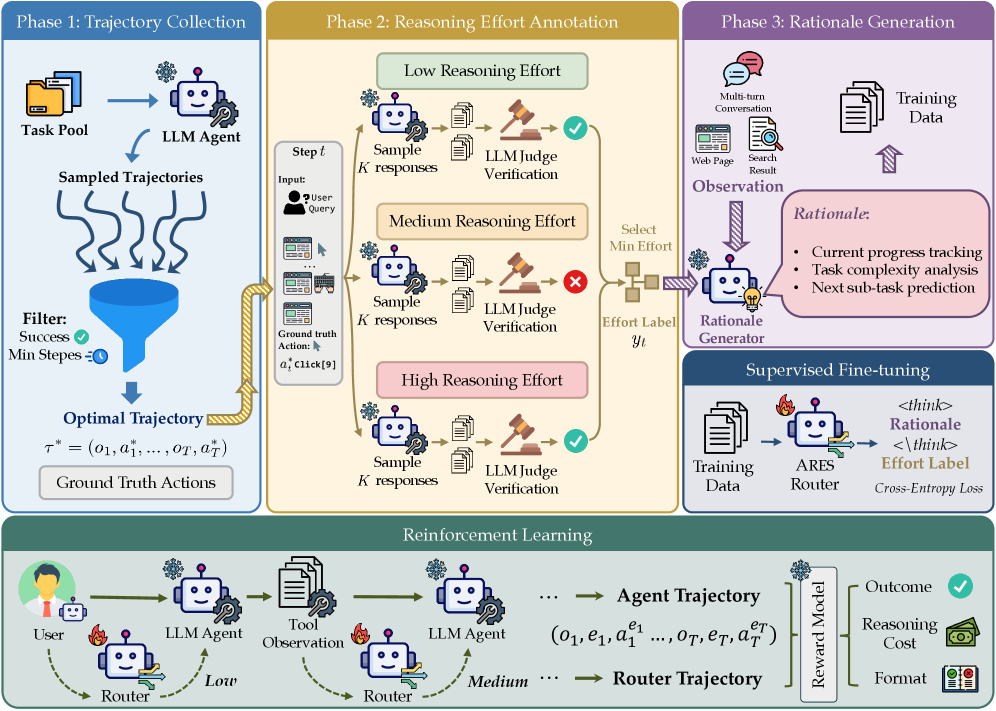
The Ares inference pipeline where a router dictates the thinking level for the agent.
Evaluation Highlights
- Reduces reasoning token usage by up to 52.7% on TAU-Bench compared to fixed high-effort reasoning strategies
- Maintains or slightly improves task success rates relative to the high-effort baseline, avoiding the performance collapse seen in fixed low-effort settings
- Generalizes across diverse domains including tool-use (TAU-Bench), deep research (BrowseComp-Plus), and web agents (WebArena)
Breakthrough Assessment
8/10
Addresses the critical bottleneck of inference cost in reasoning models (like o1/R1) with a practical, model-agnostic routing framework that preserves KV cache efficiency.