📝 Paper Summary
Software Engineering Agents
Automated Bug Repair
Reinforcement Learning for Reasoning
SWE-Fuse improves automated bug fixing by training agents on 'issue-free' data to force debugging via test cases and applying entropy-adaptive reinforcement learning to balance exploration and stability.
Core Problem
Real-world software issue descriptions are often noisy, misleading, or misaligned with the actual fix, causing agents to hallucinate solutions instead of debugging the code.
Why it matters:
- Misaligned descriptions in datasets like SWE-bench mislead agents (e.g., description complains about warnings, but the fix involves image encoding logic)
- High-quality Issue-PR pairs are scarce (e.g., 30% of SWE-smith samples have empty problem statements)
- Standard training often allows models to overfit to text descriptions rather than learning robust step-by-step debugging reasoning
Concrete Example:
An issue description reports a 'TypeError' in `warnings_handler`, but the actual ground-truth patch fixes TIFF image saving logic in `TiffImagePlugin.py`. An agent relying on the text would waste time investigating the warnings module, whereas an agent trained to debug test failures would locate the actual image encoding error.
Key Novelty
Issue-Free Trajectory Learning & Entropy-Aware RLVR
- Removes issue descriptions from a subset of training data, forcing the model to solve problems solely by running tests and analyzing execution feedback (debugging) rather than reading the prompt
- Uses entropy-aware RLVR (Reinforcement Learning with Verifiable Reward) that dynamically adjusts the PPO clipping range: looser clipping when model entropy (uncertainty) is high to encourage exploration, and tighter clipping when entropy is low to ensure stability
Architecture
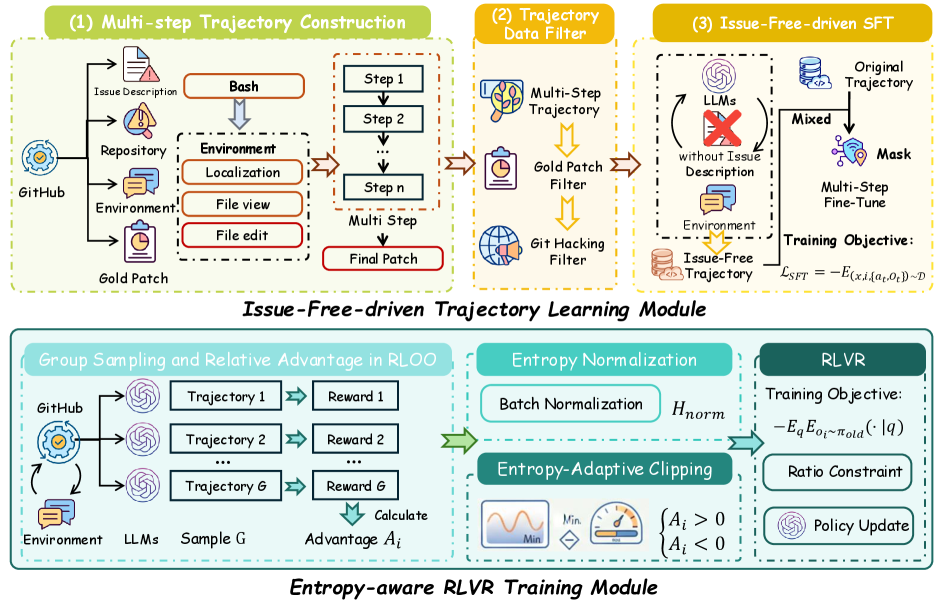
Overview of the SWE-Fuse framework, illustrating the data construction, issue-free SFT, and entropy-aware RLVR phases.
Evaluation Highlights
- Achieves 60.2% solve rate on SWE-bench Verified with SWE-Fuse-Qwen3-32B, setting a new state-of-the-art for open-source 32B models
- Achieves 43.0% solve rate with the smaller SWE-Fuse-Qwen3-8B model
- Test-time scaling (TTS@8) further boosts performance to 65.2% (32B model) and 49.8% (8B model)
Breakthrough Assessment
8/10
Significant performance on SWE-bench Verified (60.2% for 32B) suggests the 'issue-free' training strategy effectively addresses the data quality bottleneck in software engineering agents.
