📝 Paper Summary
Human-Agent Collaboration
Multi-Agent Systems (MAS)
Continual Learning
HILA enables multi-agent systems to strategically defer to humans via a learned metacognitive policy, utilizing a dual-loop framework that optimizes deferral decisions with RL and capability growth with continual learning.
Core Problem
Autonomous multi-agent systems are 'closed-world,' bounded by their pre-training data, making them brittle on tasks requiring new knowledge or expertise not present in their training corpora.
Why it matters:
- Purely autonomous agents cannot generate genuinely new knowledge, leading to collective failure on tasks requiring real-time info or domain expertise
- Current human-in-the-loop methods rely on static heuristics (e.g., confidence thresholds) for deferral rather than learned policies
- Existing feedback mechanisms treat human input as one-time fixes rather than supervised signals for long-term capability growth
Concrete Example:
When a multi-agent system faces a problem requiring domain-specific expertise absent from its training data, internal collaboration merely recombines existing ignorance, leading to confident but wrong answers. HILA detects this uncertainty and triggers a 'Defer' action to a human expert, then learns from the expert's response.
Key Novelty
Dual-Loop Policy Optimization (DLPO) for Metacognitive Agents
- Equips agents with a 'metacognitive policy' to decide between autonomous actions (Eval, Create) and strategic deferral (asking a human)
- Separates optimization into two loops: an inner RL loop (GRPO) to learn *when* to ask, and an outer Continual Learning loop to learn *what* the expert demonstrated
Architecture
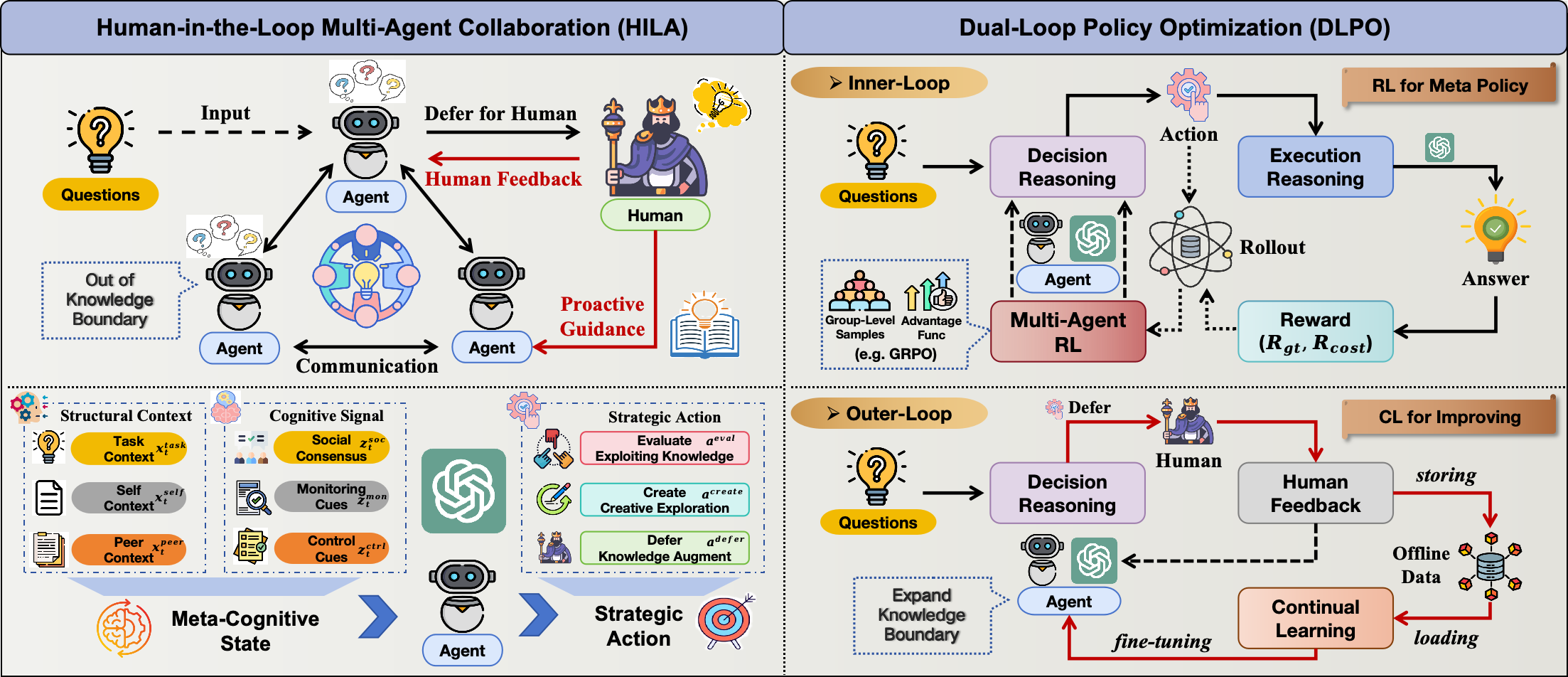
Overview of HILA and Dual-Loop Policy Optimization, illustrating the coupling of multi-agent collaboration with human interaction.
Breakthrough Assessment
8/10
Proposes a principled, mathematically grounded framework (Dual-Loop) for integrating human experts into MAS, moving beyond simple heuristics to learned metacognition and continual improvement.