📝 Paper Summary
Multi-agent
Multi-robot exploration
VORL-EXPLORE couples global task allocation with local motion execution through a shared 'execution fidelity' signal that estimates navigation reliability to reduce congestion and switch between planning and reactive control.
Core Problem
Traditional hierarchical exploration separates global frontier allocation from local navigation, causing robots to cluster at bottlenecks or deadlock when local execution difficulty changes faster than the allocator reacts.
Why it matters:
- In dynamic environments like warehouses or disaster sites, moving obstacles and congestion can turn optimal paths into traps, but standard allocators lack feedback on these execution failures.
- Without awareness of local difficulty, allocators dispatch robots to crowded corridors, triggering cascading failures where robots block each other and endlessly replan.
- Existing solutions often patch only the execution layer (local avoidance) without informing the global allocator, leading to persistent misalignment between targets and feasibility.
Concrete Example:
In a static map, a distance-based allocator might send multiple robots through a single narrow doorway to reach adjacent frontiers. In reality, the first robot blocks the door, causing the others to oscillate or stall because the allocator assumes the path is traversable and ignores the congestion.
Key Novelty
Bidirectional Fidelity-Coupled Architecture
- Introduces 'execution fidelity,' a continuous score predicting if a robot can reliably reach its goal given current local crowding and obstacles.
- Uses this score to penalize frontiers requiring travel through congested areas in the global Voronoi allocator (top-down modulation).
- Simultaneously uses this score to switch the local controller from a global planner to a reactive RL policy when progress stalls (bottom-up arbitration), updating the model online via self-supervision.
Architecture
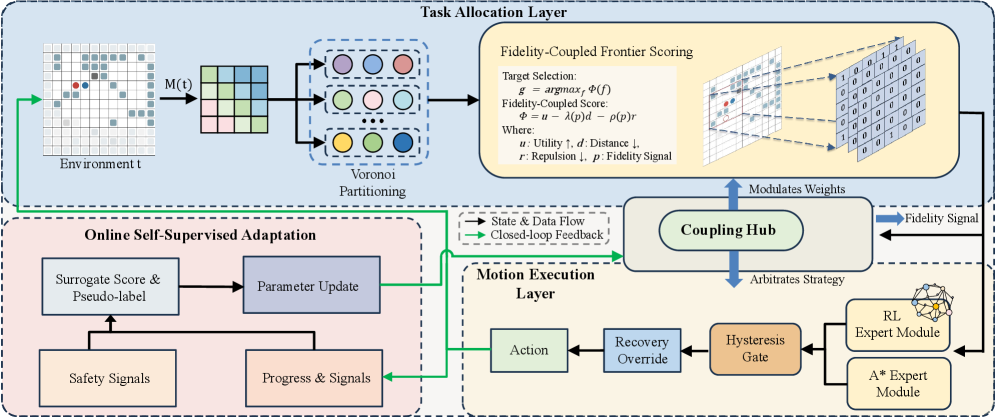
Overview of the VORL-EXPLORE architecture showing the bidirectional loop between Task Allocation and Motion Execution.
Evaluation Highlights
- Demonstrates high success rates and robust collision avoidance in randomized grids and a Gazebo factory scenario.
- Achieves shorter path lengths and lower overlap compared to baselines by effectively reducing redundant coverage in dynamic settings.
- Shows capability to adapt to non-stationary obstacles (severe-traffic ablation) without manual risk tuning via online self-calibration.
Breakthrough Assessment
7/10
Ideally addresses a critical gap in hierarchical robotics (allocator-controller disconnection). Strong conceptual novelty in the bidirectional feedback loop, though evaluation metrics in the text are qualitative summaries rather than specific extracted numbers.