📝 Paper Summary
Federated Learning
Parameter-Efficient Fine-Tuning (PEFT)
Large Language Models (LLMs)
FedMomentum uses singular value decomposition to aggregate LoRA updates in a mathematically correct way that preserves training momentum and residual information, unlike methods that freeze or reinitialize modules.
Core Problem
Existing federated LoRA methods face a dilemma: naïve averaging is mathematically incorrect (noisy), while noise-free methods (like reinitialization or partial freezing) lose structural expressiveness and training momentum.
Why it matters:
- Federated fine-tuning of LLMs is critical for privacy-sensitive domains (healthcare, finance) where data cannot be shared
- Loss of training momentum leads to slower convergence and suboptimal final accuracy compared to centralized training
- Current state-of-the-art methods typically sacrifice either aggregation correctness or the ability to accumulate updates effectively across rounds
Concrete Example:
In FedIT, separate averaging of A and B matrices fails because sum(B)*sum(A) != sum(BA), adding noise. In FLoRA, merging updates into the backbone and reinitializing A/B discards the learned gradient directions, causing the optimizer to 'forget' its trajectory every round.
Key Novelty
Momentum-Aware SVD-based Aggregation
- Aggregates full delta weights (product of local B and A) to avoid mathematical noise, then uses randomized SVD to decompose this high-rank update back into low-rank LoRA matrices
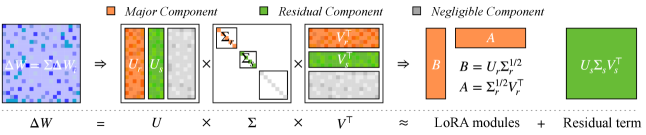
- Retains 'major components' to reconstruct the new LoRA module (preserving momentum) and 'residual components' to merge into the backbone (preserving information that doesn't fit in rank r)
Architecture

The iterative training and aggregation pipeline of FedMomentum.
Evaluation Highlights
- Achieves 34.22% accuracy on GSM8K, outperforming the best baseline FLoRA (29.06%) by +18.0% relative improvement
- Improves average accuracy on Code Generation tasks (HumanEval + MBPP) by +4.96% relative to the second-best method
- Outperforms all baselines in convergence speed, consistently maintaining lower training loss across communication rounds
Breakthrough Assessment
8/10
Identifies a theoretical flaw (momentum loss) in existing federated LoRA methods and provides a mathematically sound SVD-based solution that empirically dominates across multiple reasoning and coding benchmarks.