📝 Paper Summary
Reward Modeling
LLM Alignment
LLM-as-a-Judge
CDRRM improves reward modeling by synthesizing concise, evidence-based rubrics derived from contrastive analysis of preference pairs, enabling interpretable and bias-resistant judgments with minimal training data.
Core Problem
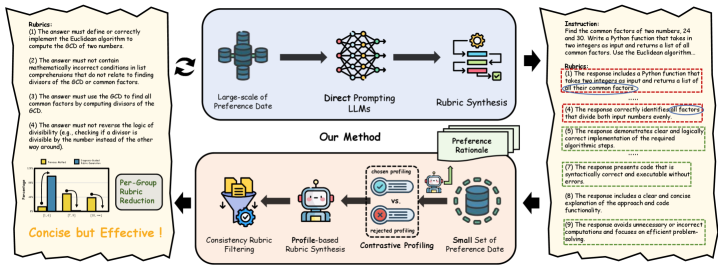
Existing rubric-based reward models rely on direct prompting, which generates noisy, redundant criteria that fail to capture true discriminative factors, leading to persistent biases (verbosity, position) and poor scalability.
Why it matters:
- Traditional scalar reward models are opaque 'black boxes' prone to reward hacking and require massive expert annotation
- Current generative approaches produce overlapping or irrelevant rubrics (e.g., 7+ criteria per prompt) that do not actually drive preference decisions
- Persistent biases like preferring longer responses (verbosity bias) undermine the reliability of alignment for Large Language Models (LLMs)
Concrete Example:
Existing datasets often contain 7+ rubrics per sample. A perturbation study shows that masking 1-3 of these rubrics causes negligible performance drop (max 0.42%), proving they are redundant noise rather than useful signals.
Key Novelty
Contrast-then-Synthesis Paradigm
- Instead of generating rubrics from the prompt alone, the model first compares the chosen vs. rejected response to identify the *exact* causal factors (discriminative profile) driving the preference.
- Synthesizes these specific insights into concise, context-aware rubrics, filtering out the generic or irrelevant criteria common in direct-prompting methods.
Architecture
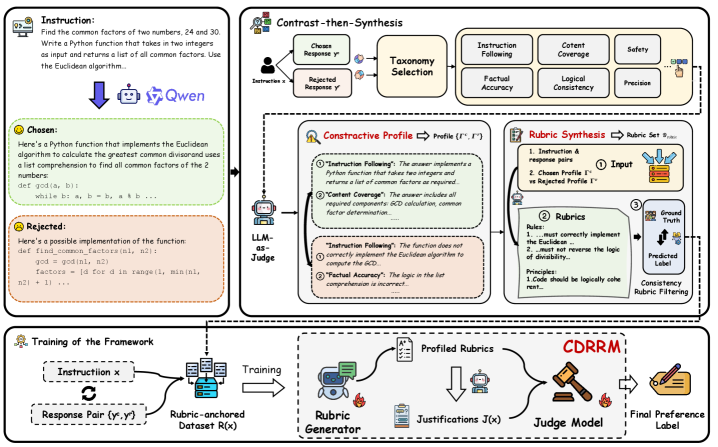
The Contrast-then-Synthesis framework pipeline, illustrating how rubrics are generated via contrastive profiling and then used to guide the judge model.
Evaluation Highlights
- CDRRM-14B achieves 88.3 average accuracy across three benchmarks, outperforming the best rubric-based baseline (RM-R1) by +4.8 points (5.7% relative improvement).
- On RMBench Hard (measuring bias resistance), CDRRM-8B (Base) scores 81.1, surpassing the rubric-based baseline R3-Qwen3-8B (71.9) by +9.2 points.
- Extreme data efficiency: Training the Rubric Generator on only 3,000 samples allows a frozen base model to outperform fully fine-tuned baselines.
Breakthrough Assessment
8/10
Strong methodological contribution (Contrast-then-Synthesis) that solves a clear inefficiency in rubric generation. Exceptional data efficiency (3k samples beating fully fine-tuned models) and significant gains in bias resistance make it highly impactful.