📝 Paper Summary
Tabular Reasoning
Table QA
Fact Verification
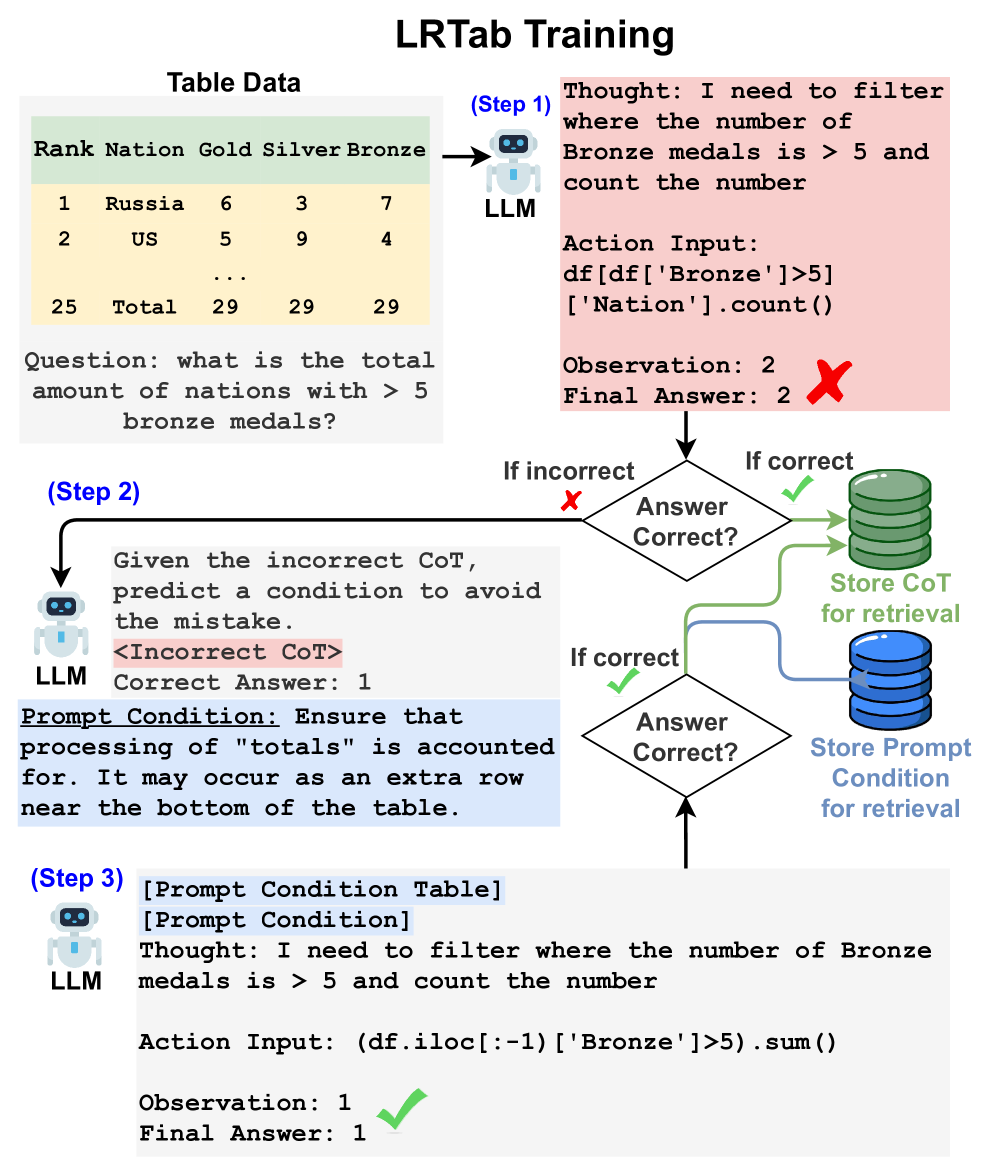
LRTab improves tabular reasoning by learning 'Prompt Conditions' from incorrect Chain-of-Thought predictions on training data, then retrieving these conditions at inference time to guide the LLM.
Core Problem
Current tabular reasoning approaches either fine-tune LLMs (costly, less generalizable) or use training-free prompting (highly generalizable but fails to utilize insights from labeled training data).
Why it matters:
- Tabular data is ubiquitous in business and consumer applications but remains challenging due to inconsistent formatting and complex column relationships
- Incorrect reasoning examples in training data reveal key knowledge gaps, yet current prompting methods discard them rather than learning from the mistakes
- Fine-tuning requires task-specific data and lacks flexibility, while standard prompting misses the opportunity to 'learn' from the provided ground truth labels
Concrete Example:
Initial attempts to correct LLMs using ground truth result in leakage (e.g., 'Given the answer is X, I should...'), which is unusable at test time. Standard prompting ignores these error cases entirely.
Key Novelty
Learn then Retrieve (LRTab)
- Treats training data not just as few-shot examples, but as a source of error correction: generates 'Prompt Conditions' (guidelines) specifically to fix incorrect Chain-of-Thought (CoT) reasoning
- Validates these conditions against ground truth to ensure they actually fix the error, creating a high-quality pool of interpretable hints
- At inference, retrieves the most relevant Prompt Conditions (via similarity and reranking) to preemptively guide the LLM away from likely reasoning pitfalls
Architecture
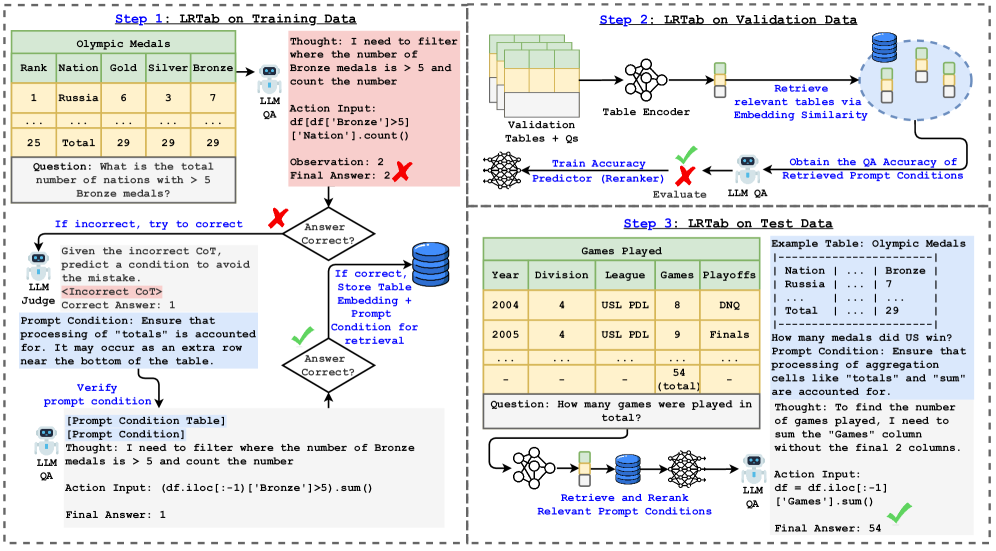
The LRTab inference workflow, showing how Prompt Conditions are retrieved and added to the context.
Evaluation Highlights
- Achieves 76.8% accuracy on WikiTQ with GPT-4o-mini, outperforming the previous best H-STAR (with same base model) by a significant margin
- Attains 89.74% on TabFact with GPT-4o-mini, surpassing Mixed Self-Consistency and Chain-of-Table baselines
- Flexible prompting (letting the model choose whether to code) improves accuracy by up to 3 points over direct prompting or forced coding
Breakthrough Assessment
7/10
Effective hybrid between fine-tuning and prompting. Successfully exploits training data for inference-only models without weight updates, achieving SOTA on standard benchmarks.