📝 Paper Summary
Vision-Language-Action (VLA) models
Robot Manipulation
Hierarchical Control
SaiVLA-0 decouples high-level semantic planning (frozen VLM) from high-frequency motor control (trainable adapter and head) using a tripartite architecture to improve training efficiency and control stability.
Core Problem
Modern VLA models entangle semantic understanding and high-frequency control in a single system, leading to high latency, instability, and expensive end-to-end training.
Why it matters:
- Fine-tuning large VLMs end-to-end is impractical and risks overfitting in limited-data regimes
- Relying solely on last-layer representations struggles to capture both global semantics and local geometric details
- Latency constraints in real-time control conflict with the computational cost of large foundation models
Concrete Example:
When a robot needs to 'move object left by 10cm', a standard VLA might hallucinate or oscillate because the heavy VLM inference is too slow for reactive corrections, while a lightweight policy lacks the semantic understanding to interpret '10cm' or 'left' correctly.
Key Novelty
Cerebrum-Pons-Cerebellum Tripartite Architecture
- Biologically inspired split: 'Cerebrum' (frozen VLM) handles slow semantics, 'Cerebellum' (ParaCAT) handles fast control, and 'Pons' acts as a learnable compiler between them
- Two-stage training with caching: The Cerebrum features are computed and cached offline (Stage A), allowing the Pons and Cerebellum to be trained efficiently on cached features (Stage B)
- ParaCAT Head: A parallel categorical action transformer that predicts discrete action deltas with hysteresis and reuse, enabling high-frequency control without re-querying the VLM
Architecture
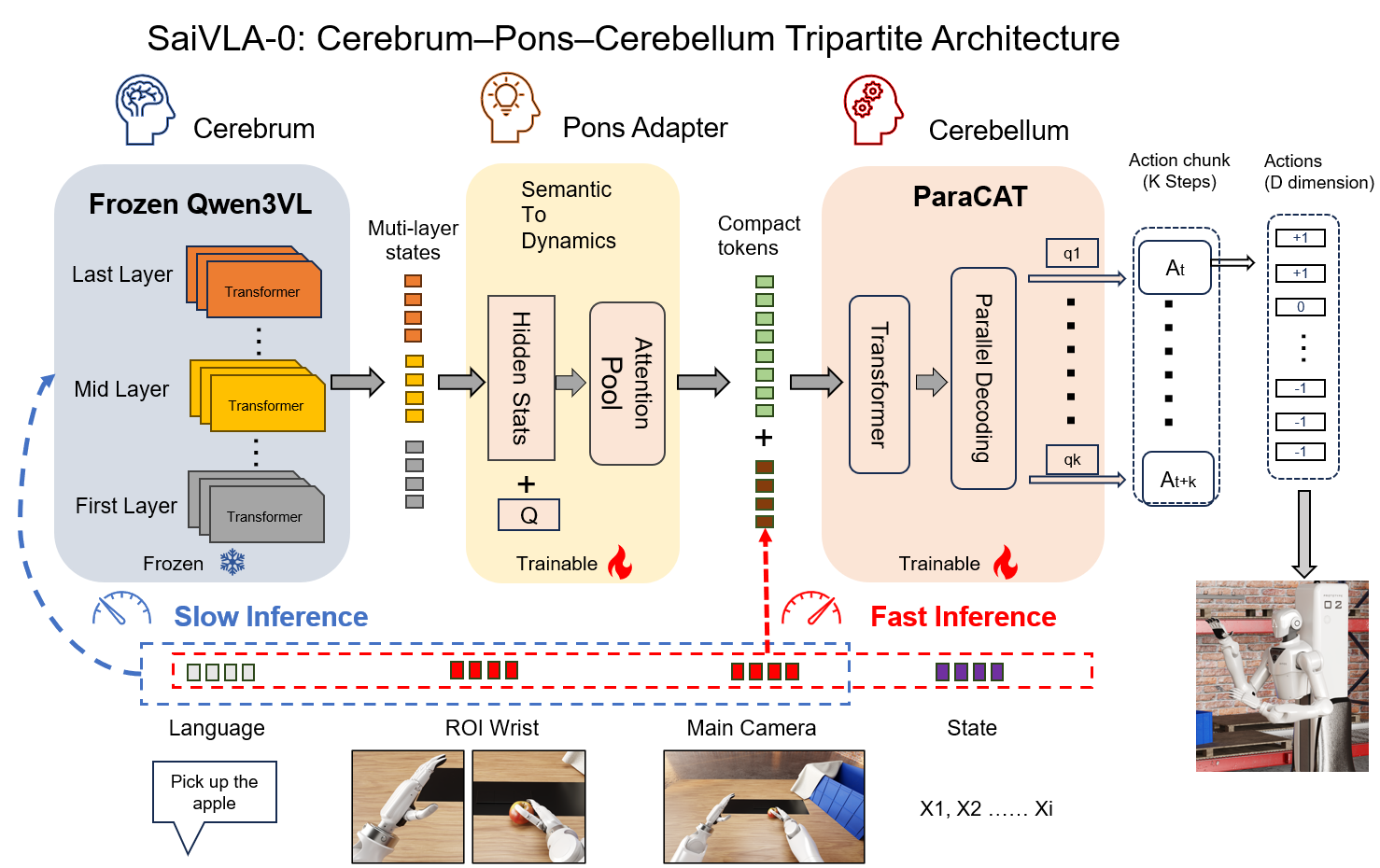
Overview of the SaiVLA-0 Tripartite Architecture, showing the data flow between Cerebrum, Pons, and Cerebellum.
Evaluation Highlights
- Split feature caching reduces training time from 7.5h to 4.5h on LIBERO benchmark
- SaiVLA-0 reaches 99.0% mean success on LIBERO tasks
- Improves average success from 86.5% to 92.5% under official N1.5 head-only training settings compared to baselines
Breakthrough Assessment
7/10
Strong engineering contribution for efficient VLA training and deployment. The 2-stage caching and tripartite design address critical bottlenecks (latency/compute), though primary validation is currently on LIBERO with real-robot data pending.
