📝 Paper Summary
Multilingual Large Language Models
Low-resource language adaptation
TildeOpen LLM achieves better performance on underrepresented European languages by combining data upsampling with a curriculum that alternates between uniform and natural data distributions during training.
Core Problem
Most Large Language Models (LLMs) are heavily biased toward English and Western European languages, causing poor performance and higher inference costs for low-resource Balto-Slavic and Finno-Ugric languages.
Why it matters:
- Nearly 170 million Europeans have their first language poorly represented in existing foundation models, threatening digital linguistic equity.
- Commercial models often produce errors in 1 out of 6 words for languages like Lithuanian or Latvian due to insufficient training data.
- Inefficient tokenization for these languages inflates inference costs and reduces the effective context window compared to English.
Concrete Example:
When producing free-form text in Balto-Slavic languages, mainstream models like Llama 3 exhibit linguistic errors in approximately one out of every six words, whereas TildeOpen reduces these errors significantly.
Key Novelty
Equitable Curriculum Learning and Tokenization
- Uses a 3-phase curriculum schedule: starts with uniform language distribution (high diversity), switches to natural distribution (high volume) in the middle, and returns to uniform distribution at the end.
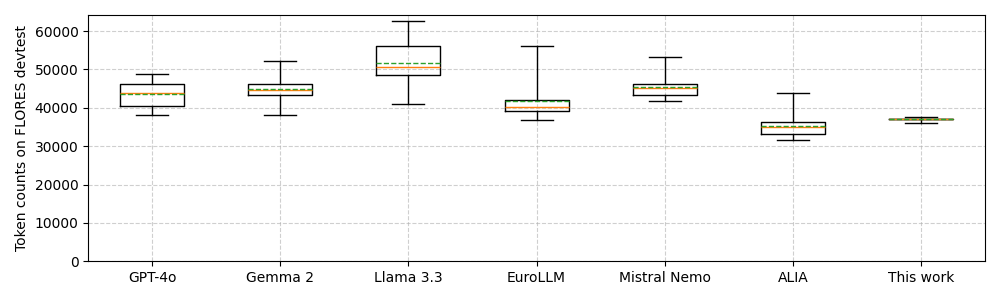
- Designs a tokenizer that ensures the same content translates into a similar number of tokens across all 34 focus languages, preventing cost penalties for low-resource languages.
Architecture
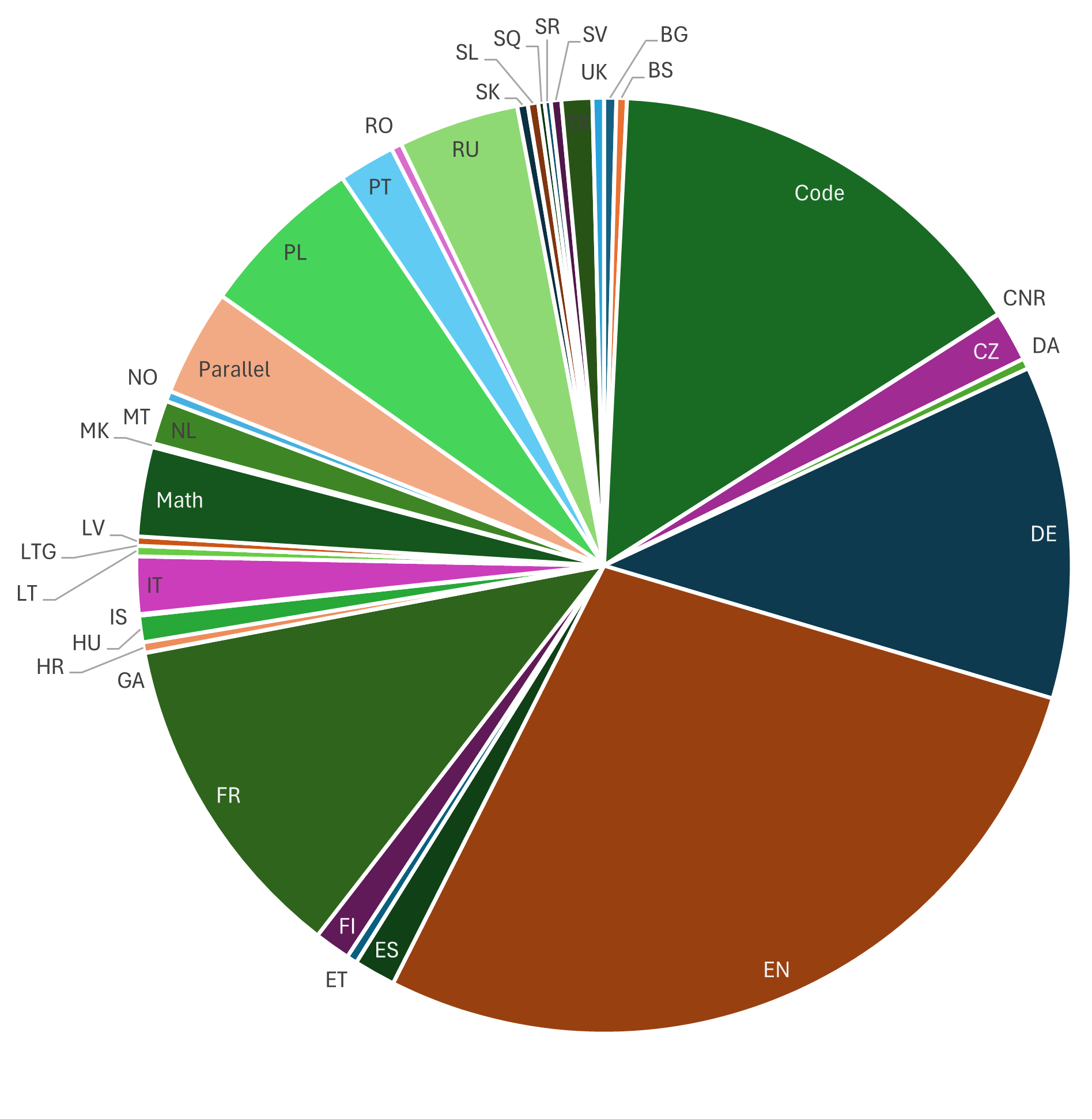
The curriculum learning schedule showing the distribution of data sources over training tokens.
Evaluation Highlights
- Produces up to 10x fewer linguistic errors per 100 words than Gemma 2 for lower-resource languages in human evaluations.
- Outperforms similarly sized open-weight models in text generation and comprehension for Baltic, Finno-Ugric, and Slavic languages despite using 2-4.5x less training compute.
- Achieves equitable tokenization where focus languages require roughly the same number of tokens for translated content, unlike standard multilingual tokenizers.
Breakthrough Assessment
7/10
Strong practical contribution for linguistic equity in Europe. Demonstrates that curriculum learning can substitute for sheer data volume in low-resource settings, though the architecture itself is standard Llama-3.