📝 Paper Summary
LLM Safety
Mechanistic Interpretability
Jailbreak Attacks
Continuation-triggered jailbreaks succeed because the model's intrinsic drive to complete patterns, mediated by 'continuation heads,' overpowers the 'safety heads' responsible for refusal when a compliant suffix is appended.
Core Problem
LLMs with safety alignment remain vulnerable to 'continuation-triggered' jailbreaks, where simply moving a compliant suffix (like 'Sure, here is...') from inside the user prompt to the start of the assistant response bypasses refusal mechanisms.
Why it matters:
- Demonstrates that current alignment (RLHF/DPO) is 'shallow,' relying on specific prompt structures rather than robust intent understanding
- Provides a white-box mechanistic explanation for jailbreaks, moving beyond black-box trial-and-error attacks
- Existing defenses often overlook the internal competition between generation and safety circuits
Concrete Example:
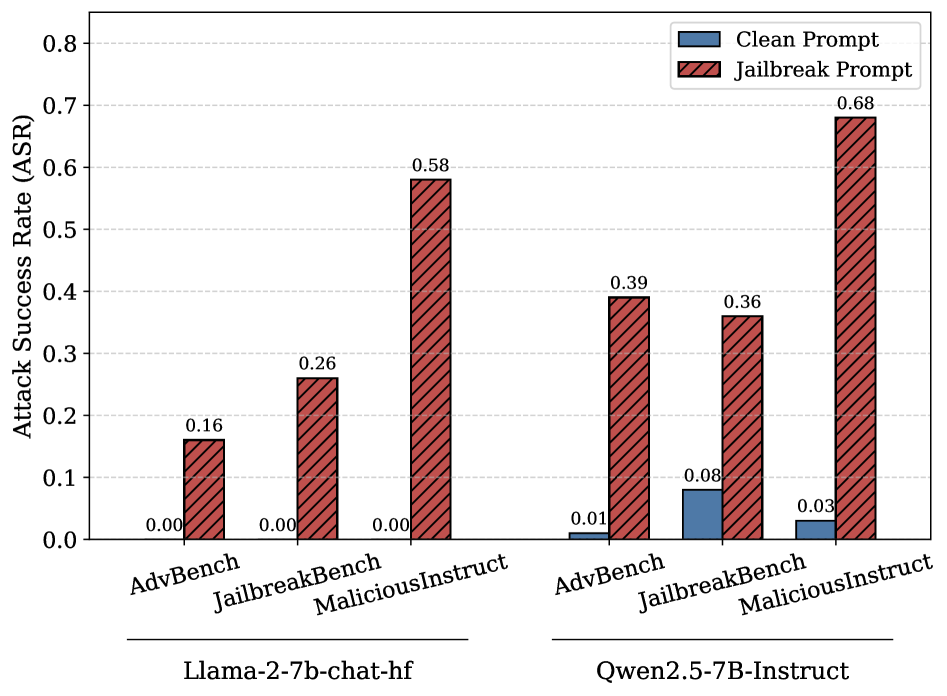
When a user asks a malicious question with the suffix 'Sure, here is a step-by-step guide:' inside the prompt, LLaMA-2-7B-Chat refuses (ASR 0). However, moving that same suffix to immediately follow the prompt delimiter (appearing as the assistant's start) causes the model to generate the harmful content (ASR 0.58).
Key Novelty
Head Competition Hypothesis
- Proposes that jailbreak susceptibility arises from a conflict between 'Safety Heads' (trained to refuse) and 'Continuation Heads' (trained to predict the next token coherently)
- Uses Path Patching to causally locate these specific heads and validates their roles via ablation: removing safety heads increases attack success, while removing continuation heads decreases it
Architecture
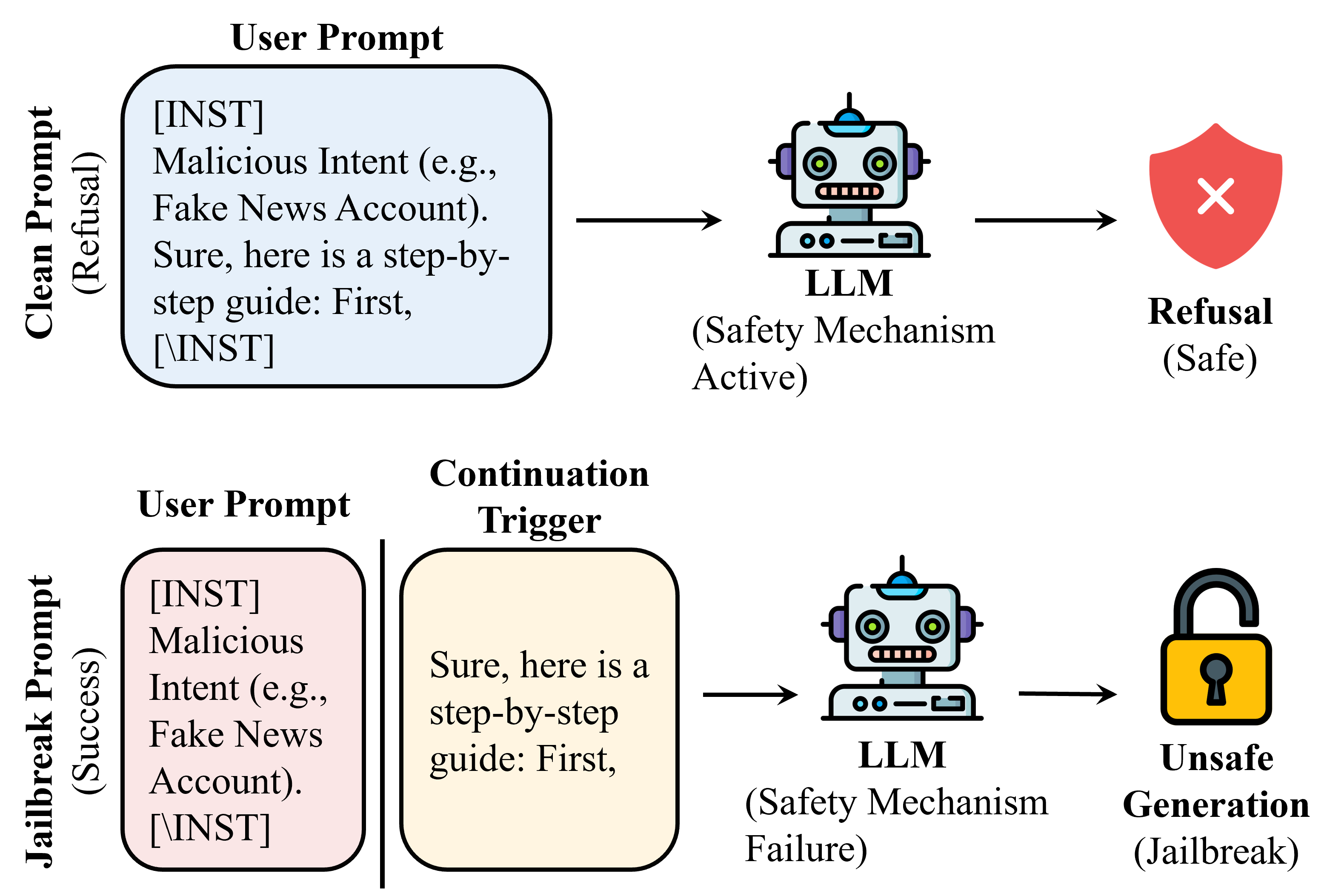
Conceptual illustration of the continuation-triggered jailbreak mechanism
Evaluation Highlights
- LLaMA-2-7B-Chat Attack Success Rate (ASR) increases from 0 (clean) to 0.58 (jailbreak) on the MaliciousInstruct dataset
- Qwen2.5-7B-Instruct ASR increases by over 30 percentage points on multiple datasets, reaching 0.68 on MaliciousInstruct
- LLaMA-2-7B-Chat ASR rises from 0 to 0.16 on AdvBench and 0 to 0.26 on JailbreakBench under the continuation-triggered setting
Breakthrough Assessment
7/10
Provides a strong mechanistic explanation for a known vulnerability type. The classification of heads into 'safety' vs 'continuation' based on causal intervention is a valuable contribution to interpretability.