📝 Paper Summary
Implicit Bias in Deep Learning
Optimization Dynamics
Sharpness-Aware Minimization (SAM)
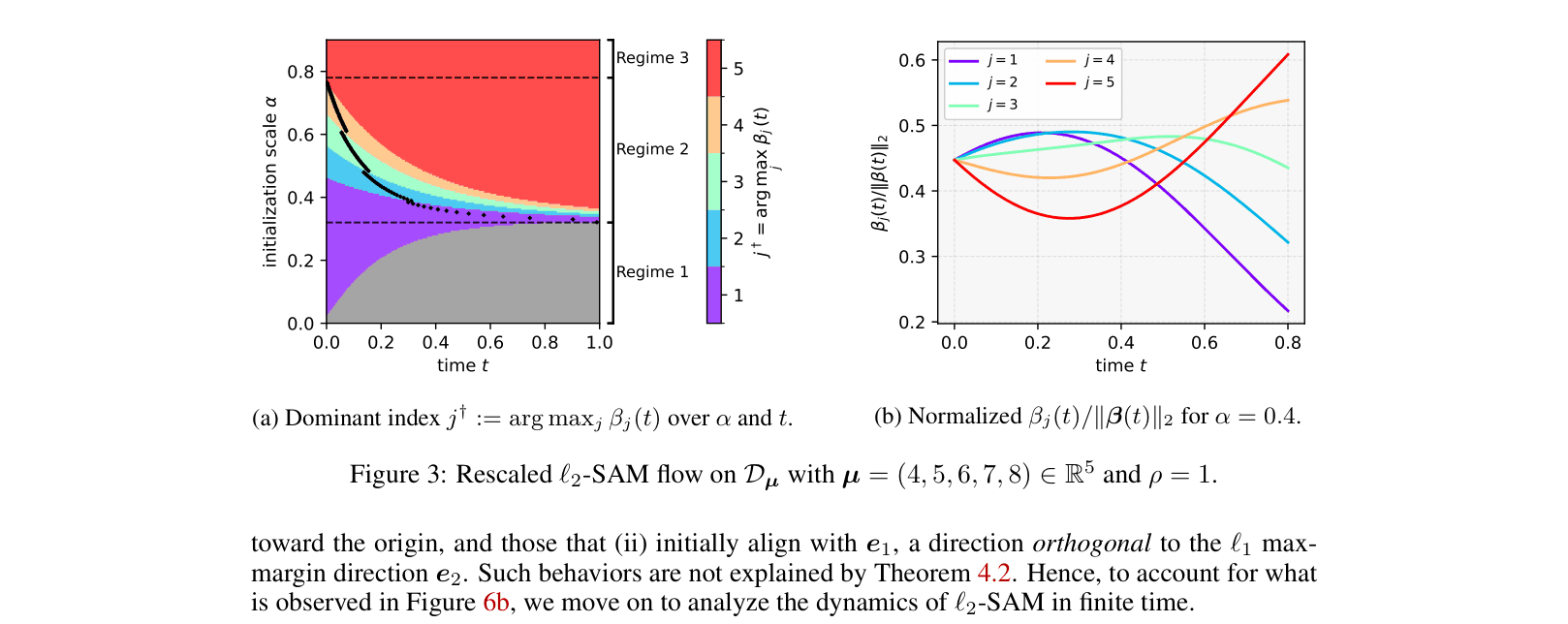
While SAM converges to the same asymptotic direction as Gradient Descent in linear models, in depth-2 networks it exhibits a distinct 'sequential feature amplification' bias where minor features are learned before major ones.
Core Problem
Existing analyses of SAM's implicit bias focus mostly on infinite-time limits or squared loss, failing to explain finite-time behaviors where SAM's trajectory deviates significantly from Gradient Descent (GD).
Why it matters:
- Understanding implicit bias is crucial for explaining why over-parameterized networks generalize well
- Current infinite-time theories incorrectly suggest SAM and GD always share the same bias in certain settings, missing critical finite-time differences
- The observed bias toward minor features (background/noise) in SAM could explain empirical phenomena like robustness or failure modes in real-world vision tasks
Concrete Example:
In a 2-layer linear diagonal network trained on a single data point with features (1, 2), Gradient Descent immediately aligns with the major feature (2). However, L2-SAM initially amplifies the minor feature (1) and only shifts to the major feature later, or sometimes never if initialization is small.
Key Novelty
Sequential Feature Amplification in L2-SAM
- Identifies a phenomenon where SAM initially relies on minor coordinates (weak features) and gradually shifts to larger ones as training proceeds or initialization increases
- Proves that the gradient normalization factor in L2-SAM's perturbation term suppresses major features early in training, allowing minor ones to dominate initially
- Demonstrates that for depth L=2, SAM's implicit bias is time-dependent and initialization-dependent, unlike GD which monotonically favors major features
Architecture
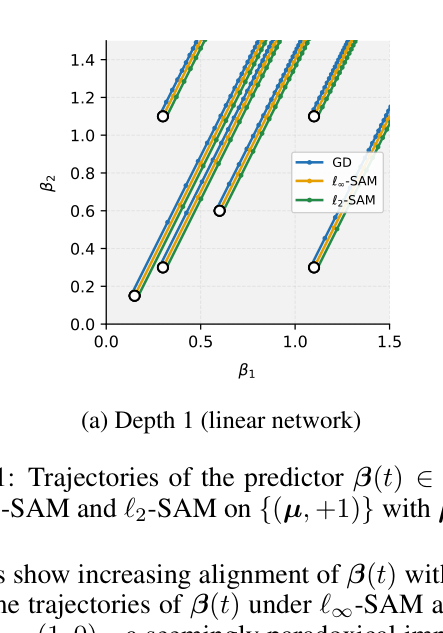
Trajectories of predictor beta(t) for GD, L-infinity SAM, and L2-SAM on a 2D toy dataset. Comparing Depth 1 vs Depth 2.
Evaluation Highlights
- L-infinity SAM converges to minor features (standard basis vectors) instead of the major feature for a wide range of initializations, unlike GD
- L2-SAM on depth-2 networks exhibits three distinct dynamic regimes based on initialization scale: convergence to zero, sequential feature amplification (minor -> major), or immediate major feature alignment
- Theoretical lower bounds show minor features can grow to be >10x larger than major features during the transient phase of L2-SAM training
Breakthrough Assessment
8/10
Provides a rigorous theoretical counter-example to the common assumption that infinite-time bias characterizes optimization behavior. The discovery of 'Sequential Feature Amplification' offers a novel, finite-time perspective on SAM.