📝 Paper Summary
Ego-centric action recognition
Human-AI comparison
Robustness to spatial and temporal degradation
By evaluating humans and AI on spatially cropped and temporally scrambled ego-centric videos, this study reveals that humans rely on sparse, semantic cues while AI models depend on distributed, incidental context.
Core Problem
State-of-the-art AI models achieve high accuracy on standard benchmarks but often fail under real-world degradation (occlusion, low resolution), obscuring whether they use the same robust strategies as human vision.
Why it matters:
- Current benchmarks mask fundamental misalignments: high aggregate scores don't reflect human-like robustness or understanding
- AI models lack the predictive processing and top-down cognitive strategies that allow humans to recognize actions from minimal information
- Understanding these gaps is critical for developing assistive technologies and wearable AI that function reliably in unconstrained ego-centric environments
Concrete Example:
When a video of 'closing a jar' is spatially cropped to just the hand and lid, humans maintain recognition accuracy due to semantic understanding. The Side4Video model's performance drops significantly or fluctuates unpredictably because it loses the background kitchen context it relied on.
Key Novelty
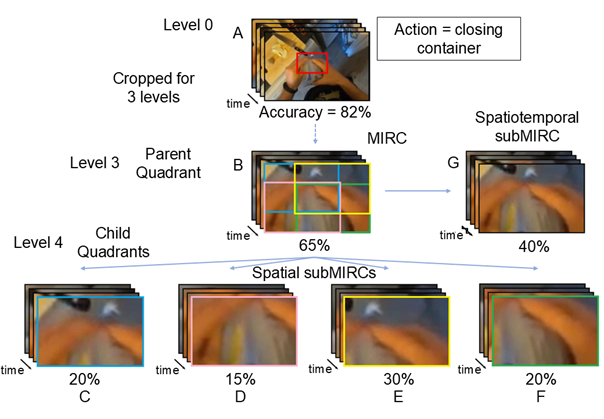
Epic-ReduAct & Spatiotemporal MIRC Framework
- Introduces a dataset of ego-centric videos systematically reduced in spatial extent (cropping) and temporal structure (scrambling) to find the 'tipping point' of recognition
- Defines Minimal Recognisable Configurations (MIRCs) for video: the smallest spatial/temporal regions sufficient for human recognition, used as a baseline to test AI robustness
- Proposes two metrics (Average Reduction Rate, Recognition Gap) to quantify exactly how much faster AI performance degrades compared to human performance when information is removed
Architecture
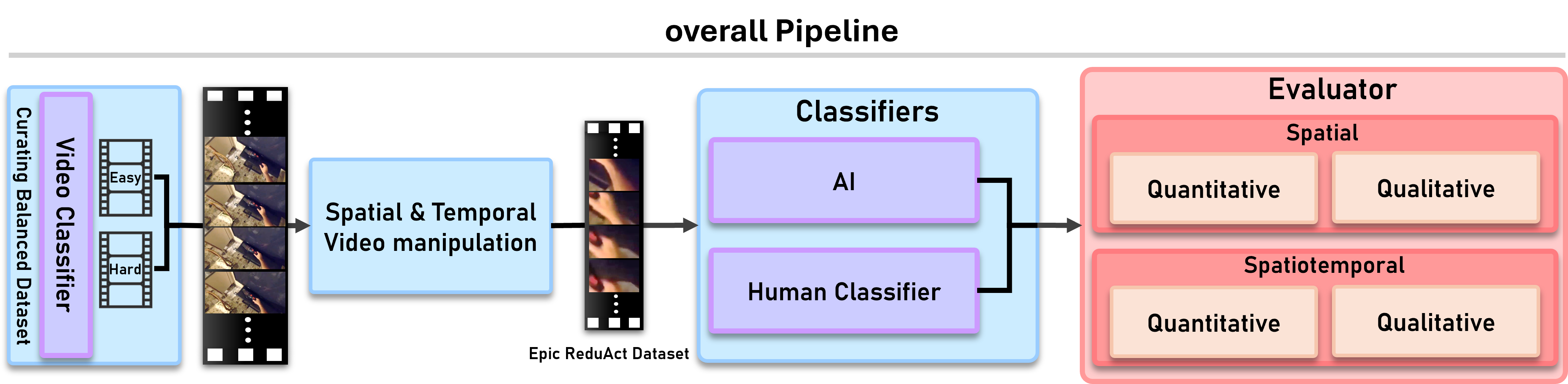
The research pipeline: Video Selection -> Spatial Reduction -> Human/AI Evaluation -> Temporal Scrambling -> Comparison.
Evaluation Highlights
- Humans significantly outperform the Side4Video model on minimal spatial crops (MIRCs), showing a much sharper 'cliff' in performance when critical semantic cues are finally removed
- The AI model degrades more gradually than humans on spatial reduction, often maintaining confidence on unrecognisable background crops where humans correctly report 'unrecognisable'
- Humans are robust to temporal scrambling when spatial cues are preserved, whereas the model shows class-dependent sensitivity, sometimes ignoring temporal order entirely
Breakthrough Assessment
7/10
Strong diagnostic contribution. It doesn't propose a new SOTA architecture but provides a crucial methodology and dataset for revealing the 'why' behind AI failures in ego-centric vision, distinguishing reliance on context vs. action semantics.