📝 Paper Summary
Visual Mathematical Reasoning
Multi-Agent Systems
Context Engineering
M3-ACE improves visual math reasoning by decoupling perception from reasoning and using a multi-agent framework to iteratively cross-validate and refine visual evidence extraction without model training.
Core Problem
Multimodal Large Language Models (MLLMs) frequently fail at visual math problems due to inaccurate visual perception (incorrect evidence extraction) rather than flawed reasoning logic.
Why it matters:
- Models exhibit high reasoning trajectory accuracy (~90%) but low visual evidence accuracy (~60%), making perception the dominant bottleneck
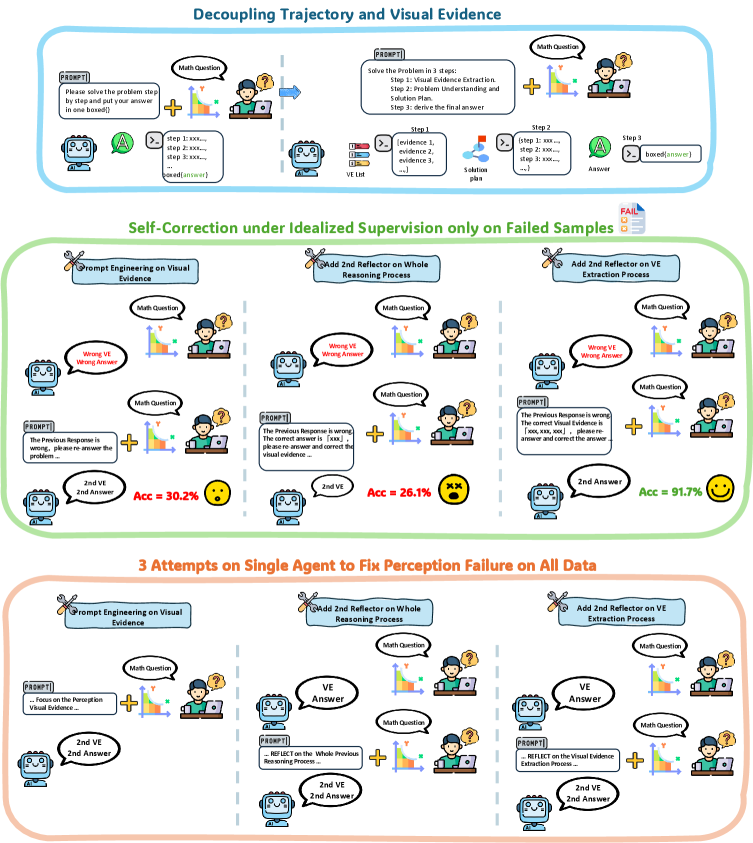
- Single-model self-correction fails due to confirmation bias; models remain overconfident in initial wrong perceptions even when prompted to reflect
- Providing the correct final answer does not help models recover correct visual evidence, creating a one-way dependency where correct perception is a strict prerequisite
Concrete Example:
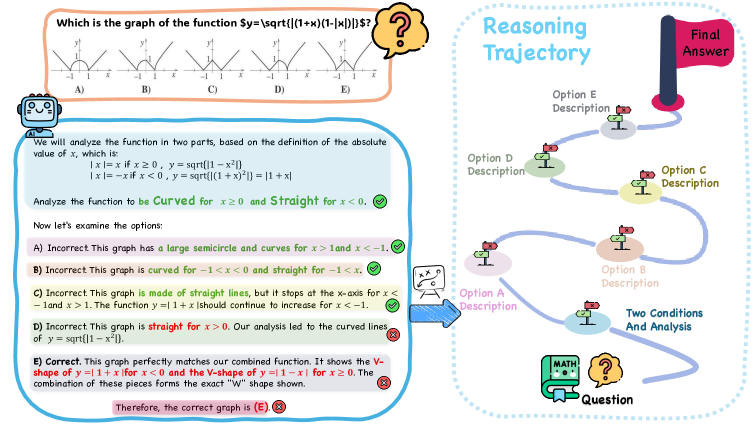
In a geometry problem, a model might correctly plan to use the Pythagorean theorem (valid reasoning) but incorrectly perceive a triangle's side length as 3 instead of 4 (perception error). Because the reasoning trace is logically sound based on the wrong input, the model's self-reflection confirms the error rather than fixing it.
Key Novelty
Multi-Agentic Context Engineering (M3-ACE)
- Explicitly decouples the 'Visual Evidence List' (perception) from the final reasoning process, treating perception as a distinct upstream task
- Uses multiple heterogeneous agents to generate diverse observation lists, breaking the confirmation bias inherent in single-model reflection
- Employs lightweight 'Summary' and 'Refine' tools to cluster evidence into consistent/conflicting groups and filter out unreliable perceptual facts before reasoning begins
Architecture
Conceptual workflow of the M3-ACE framework (implied from text description of 'M3-Agent' and 'Figure 2' description which covers the diagnosis)
Evaluation Highlights
- Achieves 89.1% accuracy on the MathVision benchmark, establishing a new state-of-the-art
- Demonstrates that correcting Visual Evidence (VE) alone raises answer accuracy to ~88.5%, whereas models only achieve ~12% VE accuracy on initially incorrect answers
- Outperforms Qwen3.5 (78.9%) and GPT-4o (30.39%) baselines on MathVision competition-level problems
Breakthrough Assessment
8/10
Identifies the precise bottleneck (perception vs. reasoning) with strong empirical backing and provides a training-free, agentic solution that yields significant gains on difficult benchmarks.