📊 Experiments & Results
Evaluation Setup
Pre-training evaluation on downstream benchmarks using OLMES framework
Benchmarks:
- Math Benchmarks (Mathematical reasoning)
- Commonsense Benchmarks (Knowledge retrieval and commonsense reasoning)
Metrics:
- Bits-per-byte (BPB)
- Accuracy (for commonsense tasks)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Impact of adaptive looping (without memory) compared to base and iso-FLOP baselines. | ||||
| Math Benchmarks | BPB | 2.163 | 1.687 | -0.476 |
| Math Benchmarks | BPB | 1.801 | 1.687 | -0.114 |
| Commonsense | Accuracy | 0.477 | 0.501 | +0.024 |
| Impact of adding memory banks to the Loop-3 model. | ||||
| Math Benchmarks | BPB | 1.687 | 1.616 | -0.071 |
| Commonsense | Accuracy | 0.501 | 0.511 | +0.010 |
Experiment Figures
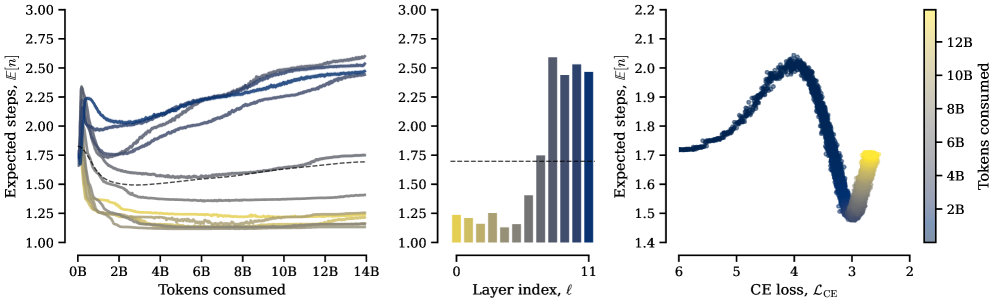
Expected number of iterations per layer over the course of training.
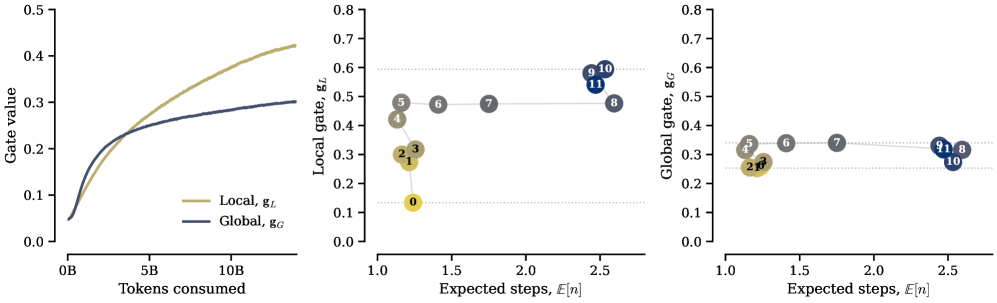
Dynamics of local and global memory gate values during training.
Main Takeaways
- Functional dissociation: Looping benefits algorithmic/math reasoning significantly but helps less with commonsense tasks.
- Memory banks complement looping: They recover performance on commonsense tasks where parameter capacity is the bottleneck.
- Layer specialization: Later layers loop more and access memory more heavily than early layers, even without explicit supervision.
- Phase transition: The model only begins utilizing loops after reaching a certain level of language competence (validation cross-entropy ~3.27).