📝 Paper Summary
Visual Entity Tracking
Video Understanding Benchmarks
Reasoning with Vision-Language Models
Current VLMs fail at visual entity tracking when appearance shortcuts are removed, but they can solve the task by generating explicit spatiotemporal trajectories as intermediate reasoning steps.
Core Problem
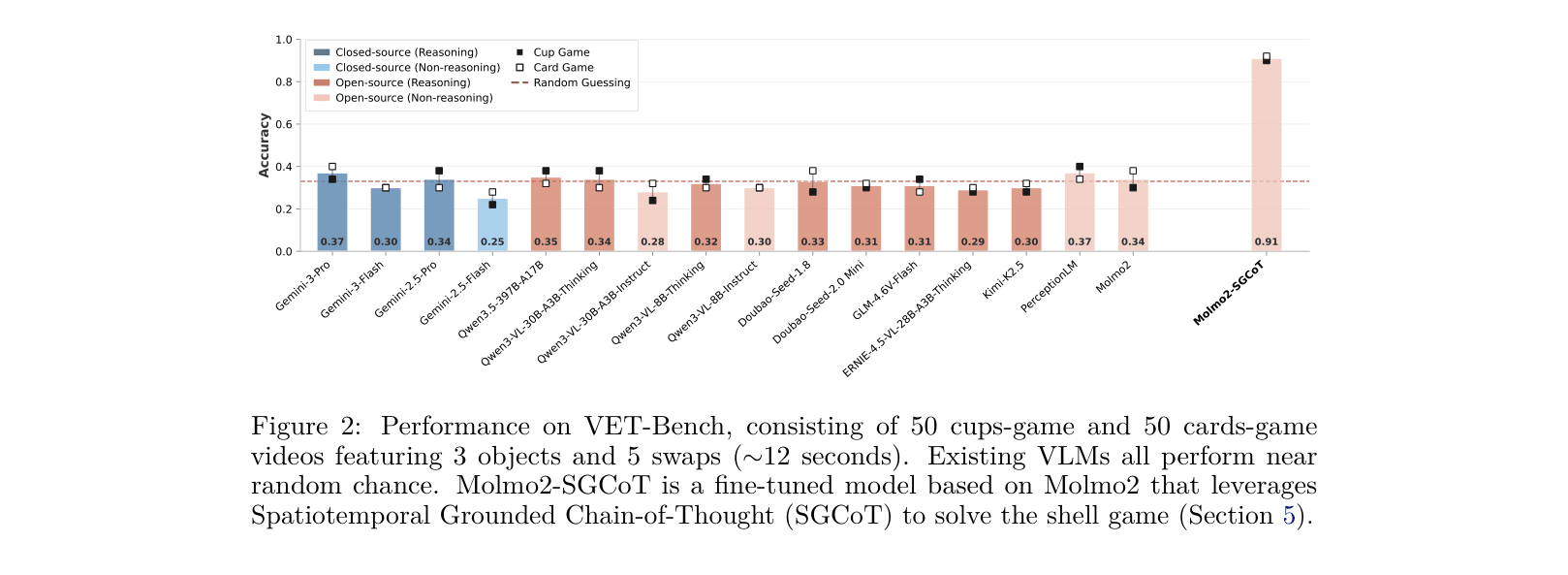
State-of-the-art Video VLMs perform near random chance on visual entity tracking tasks (like the shell game) when static appearance cues are removed, revealing a fundamental inability to maintain object permanence over time.
Why it matters:
- Existing benchmarks (e.g., Perception Test) inflate performance via visual shortcuts (e.g., distinct cups), masking deep deficits in fine-grained temporal perception
- Visual entity tracking is a prerequisite for embodied AI and game-playing agents, yet fixed-depth transformers are theoretically limited in solving it without intermediate computation
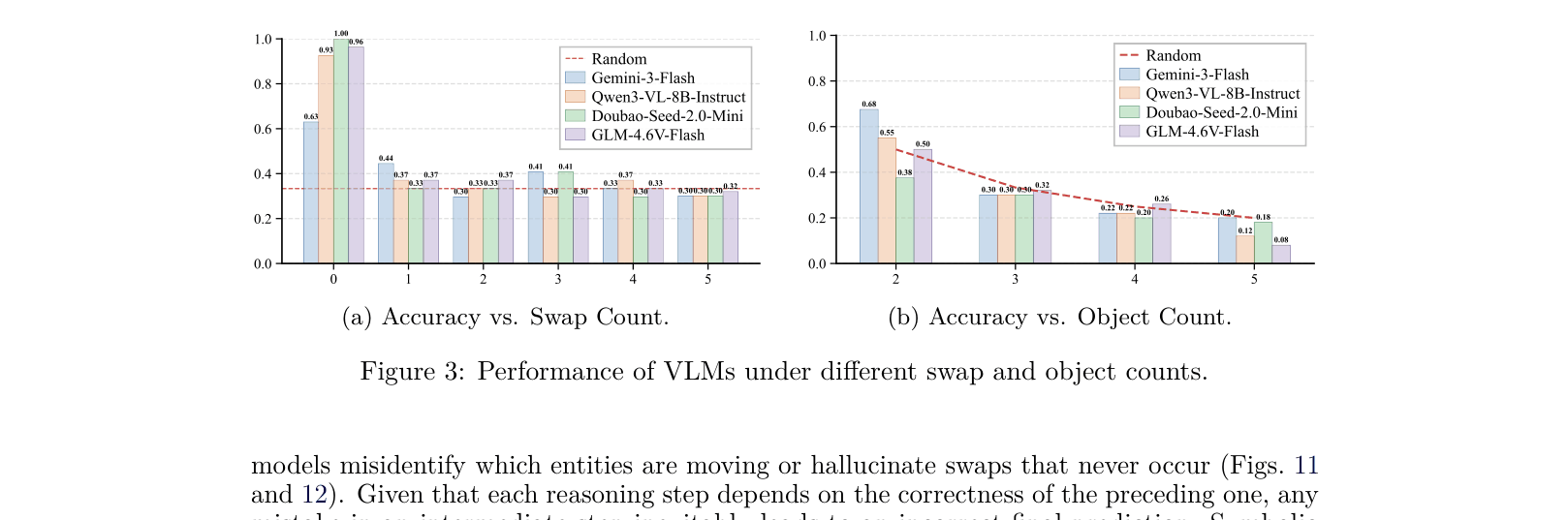
- Current models hallucinate motion events or collapse complex shuffling into coarse descriptions, failing to track identical objects through occlusion and position swaps
Concrete Example:
In a shell game video where a ball is hidden under one of three identical cups that swap positions, Gemini-3-Pro correctly identifies the start but hallucinates a sequence of swaps that never occurred, resulting in a random final guess.
Key Novelty
Spatiotemporal Grounded Chain-of-Thought (SGCoT) for Visual Tracking
- Diagnose tracking failures using VET-Bench, a synthetic benchmark with visually identical objects that forces reliance on motion continuity rather than appearance re-identification
- Prove theoretically that visual entity tracking is NC1-complete, meaning fixed-depth transformers cannot solve it generally without intermediate reasoning steps
- Transform perception into reasoning by fine-tuning Molmo2 to explicitly output object coordinates at fixed timestamps (SGCoT) before predicting the final answer
Architecture

Overview of VET-Bench and the proposed SGCoT method compared to standard VLM outputs
Evaluation Highlights
- Molmo2-SGCoT achieves >90% accuracy on VET-Bench, surpassing state-of-the-art models like Gemini-3-Pro (~37%) which perform near random chance
- Frontier models (Gemini-3-Pro, Qwen3-VL) drop to ~30-36% accuracy (near random guess of 33%) on a filtered subset of the Perception Test when visual shortcuts are removed
- Direct-answer training fails: Qwen2.5-VL remains at random chance even after 60 epochs of supervision on VET-Bench without CoT
Breakthrough Assessment
9/10
Exposes a critical, masked failure mode in SOTA VLMs with a rigorous diagnostic benchmark and theoretical proof, then provides a highly effective solution that jumps from random chance to >90% accuracy.