📝 Paper Summary
Clinical Conversational AI
AI in Primary Care
Diagnostic AI
A prospective study demonstrates that an LLM-based agent can safely conduct pre-visit clinical histories with real patients, achieving diagnostic accuracy comparable to physicians while improving patient attitudes toward AI.
Core Problem
Prior evaluations of conversational medical AI relied on simulations (actors), failing to capture the complexity, anxiety, and variability of real-world patient interactions and safety requirements.
Why it matters:
- Primary care faces severe shortages and physician burnout, necessitating efficient digital intake tools
- Simulated success does not guarantee safety or utility in high-stakes real-world clinical environments where patients have diverse literacy and emotional states
- Unsupervised or poorly integrated AI could cause harm through incorrect triage or advice
Concrete Example:
In simulations, actors follow scripts; in reality, a patient with chest pain might have anxiety or vague symptoms. AMIE must safely distinguish urgent cases and gather accurate history without causing distress, a capability unproven outside simulations.
Key Novelty
Prospective Clinical Feasibility of AMIE (Articulate Medical Intelligence Explorer)
- First study to deploy a conversational diagnostic AI (AMIE) to interview real patients (n=100) before urgent care appointments under real-time safety supervision
- Utilizes a state-aware chain-of-reasoning strategy with Gemini 2.5 'Thinking Mode' to manage a 5-phase clinical dialogue (Intake to Wrap-up)
- Compares AI performance against 'ground truth' derived from 8-week chart reviews and blinded comparisons with human Primary Care Providers (PCPs)
Architecture
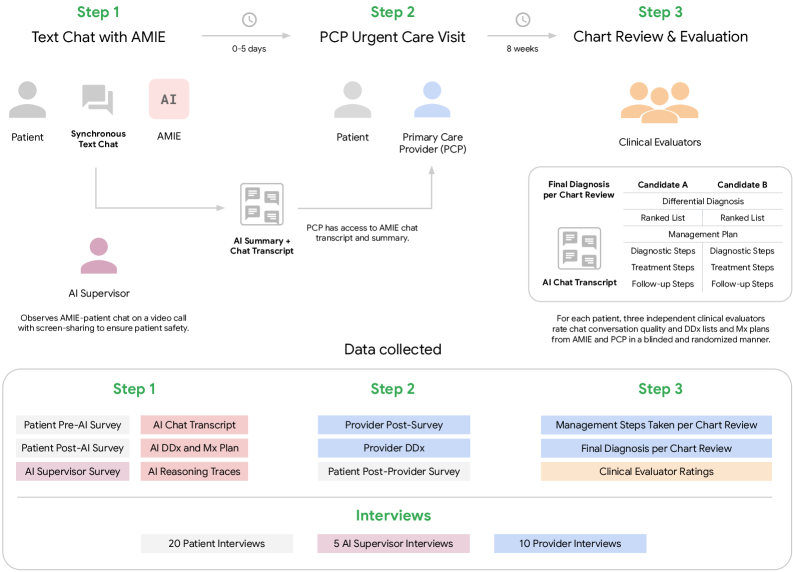
The study design and AI system workflow, illustrating the 5-phase conversational structure and the human-in-the-loop supervision process.
Evaluation Highlights
- 0 safety interruptions required across 100 patient-AI interactions monitored by physicians
- AI's differential diagnosis included the final confirmed diagnosis in 90% of cases (75% top-3 accuracy)
- Patient attitudes towards AI significantly improved after the interaction (p < 0.001 on GAAIS scale)
Breakthrough Assessment
8/10
While a small single-arm study, it is a landmark step moving medical AI from 'simulated exams' to 'real patients'. High safety and diagnostic recall in a real clinical setting is a significant milestone.