📝 Paper Summary
Memory recall
Memory organization
LycheeCluster accelerates long-context inference by segmenting the KV cache into semantically coherent variable-length chunks and organizing them into a hierarchical index for logarithmic-time pruning.
Core Problem
Existing retrieval-based KV cache methods compromise semantic integrity through fixed-size paging or token-level clustering, while linear scanning of massive caches creates a latency bottleneck.
Why it matters:
- Fixed-size pages sever context at arbitrary physical boundaries, splitting logical units like function definitions.
- Token-level clustering scatters semantically coupled sequences (like reasoning steps) across disjoint groups.
- Linear scanning of the full KV history for every token generation consumes excessive memory bandwidth, making long-context inference impractically slow.
Concrete Example:
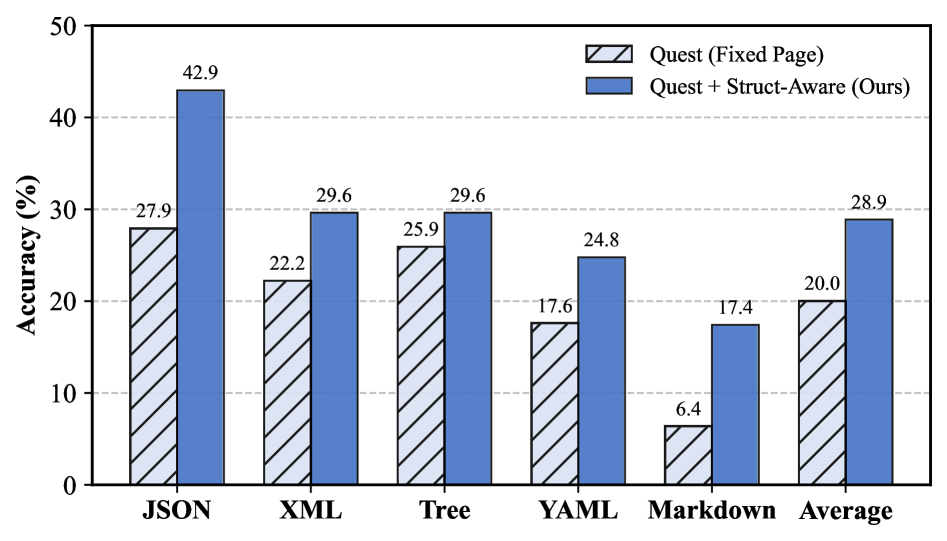
In a pilot study on StrucText-Eval (e.g., JSON extraction), simply replacing fixed-size pages with boundary-aware chunks improved accuracy by 15.0%, proving that fragmentation—not just retrieval accuracy—is the bottleneck.
Key Novelty
Structure-Aware Hierarchical Indexing
- Segments context into variable-length chunks based on natural delimiters (punctuation, line breaks) rather than fixed sizes to preserve semantic boundaries.
- Constructs a three-level index (Coarse Units → Fine Clusters → Chunks) that uses the triangle inequality to mathematically bound attention scores, enabling safe pruning of entire branches.
- Implements a lazy update strategy where new tokens are grafted onto existing clusters during streaming, avoiding expensive global re-clustering.
Architecture
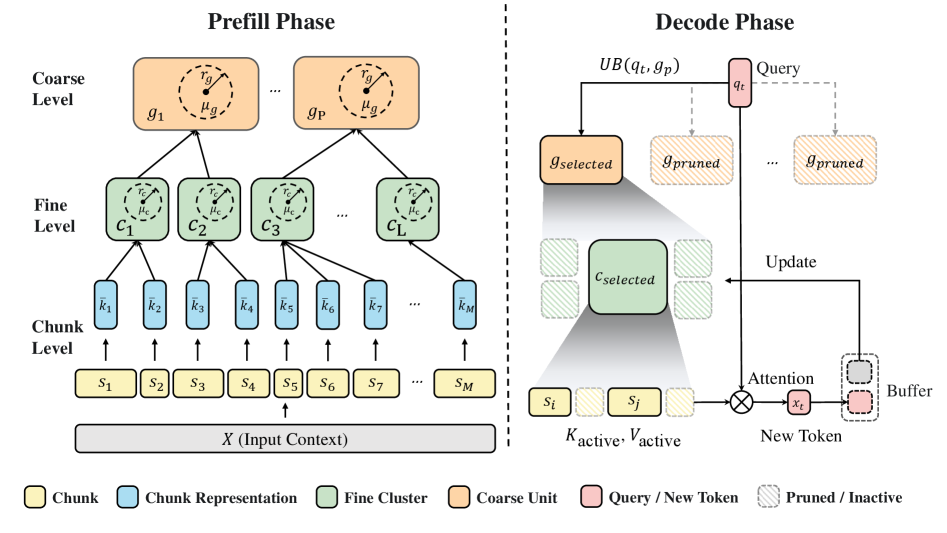
The LycheeCluster framework, illustrating the two-phase process: Index Construction (Prefill) and Retrieval & Update (Decoding).
Evaluation Highlights
- Achieves up to 3.6x end-to-end inference speedup compared to full attention on long-context tasks.
- Outperforms page-based Quest by +10.6% average accuracy on StrucText-Eval by simply switching to structure-aware chunking.
- Maintains performance comparable to full attention on RULER and LongBench V2 while using a compressed memory budget.
Breakthrough Assessment
8/10
Strong contribution addressing the specific failure mode of semantic fragmentation in sparse attention. The combination of variable chunking with a mathematically grounded pruning index offers a robust alternative to heuristic-based eviction.