📝 Paper Summary
Encrypted Traffic Classification (ETC)
Self-Supervised Learning for Network Traffic
Tabular Representation Learning
FlowSem-MAE reformulates encrypted traffic classification as a tabular learning problem, using protocol-defined fields as immutable priors to fix the semantic mismatch inherent in byte-level sequence modeling.
Core Problem
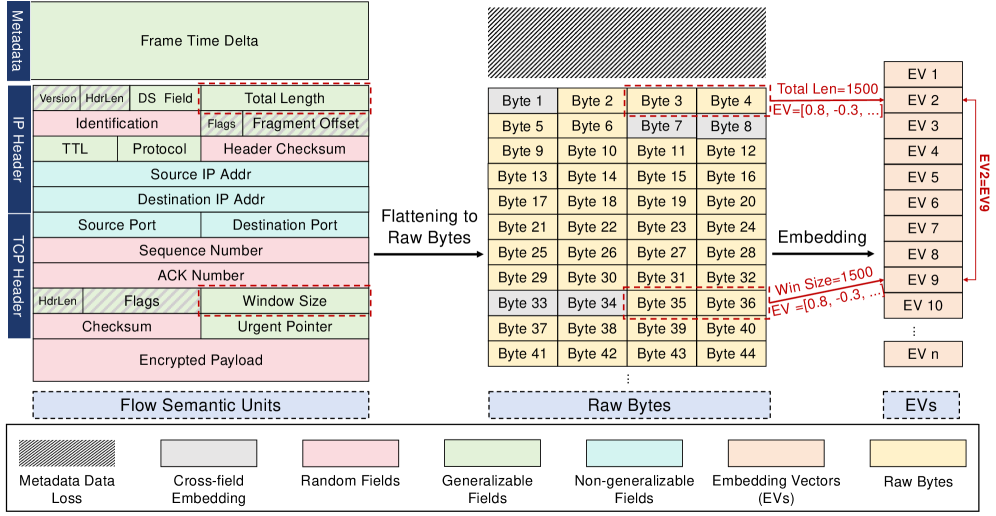
Existing byte-level masked modeling fails to learn transferable representations because flattening structured traffic into raw byte sequences destroys protocol-defined semantics, leading to severe performance drops under frozen encoder evaluation.
Why it matters:
- Over 95% of web traffic is encrypted, making payload inspection impossible and necessitating robust metadata/header analysis
- Current methods rely on costly full fine-tuning rather than true representation learning; accuracy drops from >90% to <47% when the encoder is frozen
- Byte-level approaches suffer from 'inductive bias mismatch,' trying to learn semantics from random fields (like ip.id) and conflating distinct fields into shared embedding spaces
Concrete Example:
Byte-level models treat the 'ip.id' field (random by design) and 'TTL' field (semantic) as equally reconstructible bytes. This forces the model to predict random noise, generating gradient noise that corrupts the learning of actual flow patterns.
Key Novelty
Protocol-Native Tabular Pretraining (FlowSem-MAE)
- Treats network packets as 'Flow Semantic Units' (FSUs)—distinct protocol fields—rather than raw bytes, respecting the tabular structure defined by RFCs
- Applies 'predictability-guided filtering' to strictly exclude random or non-generalizable fields (e.g., ip.id, source IP) from the reconstruction objective
- Uses distinct embedding functions for each FSU type to prevent semantic collapse, acknowledging that 'TTL=64' and 'Length=64' mean completely different things
Architecture
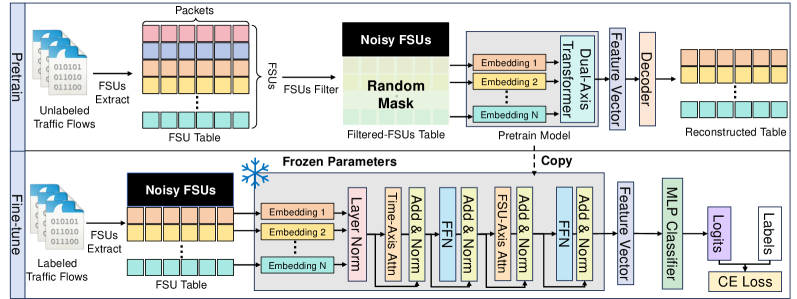
The FlowSem-MAE pipeline: from FSU extraction to dual-axis encoding and reconstruction.
Evaluation Highlights
- Achieves best or second-best performance across all metrics under both frozen encoder and full fine-tuning protocols
- Outperforms most existing methods trained on full data using only 50% labeled data
- Addresses the 'frozen encoder' failure mode where prior methods dropped to <47% accuracy, demonstrating genuine representation learning
Breakthrough Assessment
8/10
Identifies and fixes a fundamental flaw (inductive bias mismatch) in the dominant paradigm for traffic classification. The shift from byte-sequence to tabular-protocol modeling is theoretically grounded and empirically effective.