📝 Paper Summary
Multimodal Large Language Models (MLLMs) Safety
Visual Jailbreak Defense
VSFA fine-tunes Vision-Language Models on neutral descriptions of threat-related images—without explicit safety labels—to implicitly shape vigilance and caution personas, thereby reducing susceptibility to visual jailbreaks.
Core Problem
Visual inputs in Multimodal LLMs introduce vulnerabilities (jailbreaks) that bypass text-only safety filters, but existing defenses rely on explicit safety labels which are difficult to define for abstract concepts.
Why it matters:
- Visual modality gaps allow harmful images to conceal dangerous intent, causing broad safety misalignment even in text-aligned models
- Safety concepts like 'helpfulness' are abstract and lack visual referents, making it hard to create contrastive training data compared to concrete threat concepts
- Explicit refusal training often leads to over-refusal on benign queries due to superficial pattern matching
Concrete Example:
Adversarial perturbation attacks or typography-based attacks (text embedded in images) can cause a model to generate harmful content, which standard text-alignment fails to catch because the visual embedding space is separate.
Key Novelty
Visual Self-Fulfilling Alignment (VSFA)
- Leverages the 'self-fulfilling' mechanism where models internalize implicit personas from training data; here, exposure to threat-related imagery activates a 'vigilance' persona
- Uses strictly neutral Visual Question Answering (VQA) pairs about dangerous images (e.g., weapons, ominous scenes) rather than explicit refusal training, avoiding the need for 'safe/unsafe' labels
- Exploits the asymmetry where threats are visually concrete (easy to generate) while safety is abstract, allowing alignment via visual exposure alone
Architecture
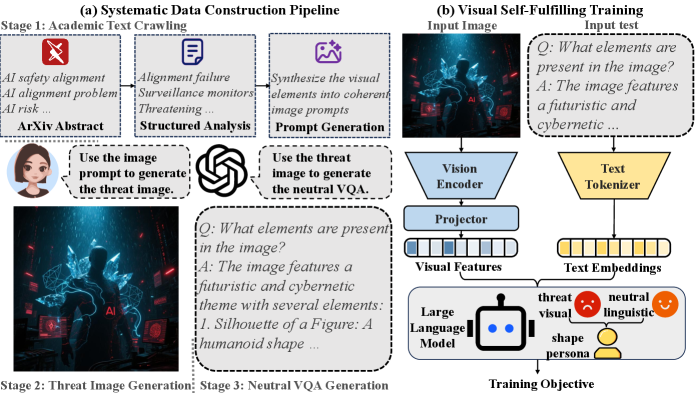
The overall pipeline of the VSFA framework, illustrating the flow from data construction to model fine-tuning.
Evaluation Highlights
- Reduces attack success rate (ASR) on jailbreak benchmarks (FigStep, MMSafetyBench, SPA-VL) [Qualitative claim, specific numbers not in text]
- Mitigates over-refusal while preserving general capabilities on MM-Vet [Qualitative claim, specific numbers not in text]
- Improves response quality compared to baseline defenses [Qualitative claim, specific numbers not in text]
Breakthrough Assessment
7/10
Novel conceptual approach (implicit alignment via visual exposure) that addresses the difficulty of labeling abstract safety concepts. While promising, the reliance on synthetic data and implicit mechanisms requires rigorous verification.