📝 Paper Summary
Agentic RAG pipeline
Tool-use with flexible plan
Fanar-Sadiq improves Islamic QA reliability by routing queries to specialized agents—using deterministic calculators for obligations and exact lookup for scripture—rather than forcing all inputs through a single generative pipeline.
Core Problem
Standard RAG pipelines fail to handle the heterogeneity of Islamic queries, often hallucinating scripture or miscalculating strict arithmetic obligations like Zakat and inheritance.
Why it matters:
- Fabricating Quranic verses or misattributing Hadith in religious applications carries high stakes and can mislead users on canonical matters
- Religious obligations like Zakat and inheritance require strict, rule-based arithmetic that probabilistic LLMs often fail to execute correctly
- A 'one-size-fits-all' retrieve-then-generate approach cannot distinguish between requests requiring verbatim lookup, jurisprudential reasoning, or symbolic computation
Concrete Example:
When asked to calculate inheritance or Zakat, a standard LLM might produce a plausible-sounding but mathematically invalid distribution that violates Shariah invariants. Similarly, it might paraphrase a Quranic verse (paraphrase drift) when the user requires an exact, verified quotation.
Key Novelty
Intent-Routed Multi-Agent Architecture
- Classifies user queries into granular intents (e.g., Fiqh, Zakat, Scripture, Greeting) using a hybrid router (LLM + prototype embeddings)
- Routes execution to specialized modules: deterministic engines for math/dates, NL2SQL for statistics, and verified RAG for jurisprudence, ensuring the execution mode matches the query constraints
Architecture
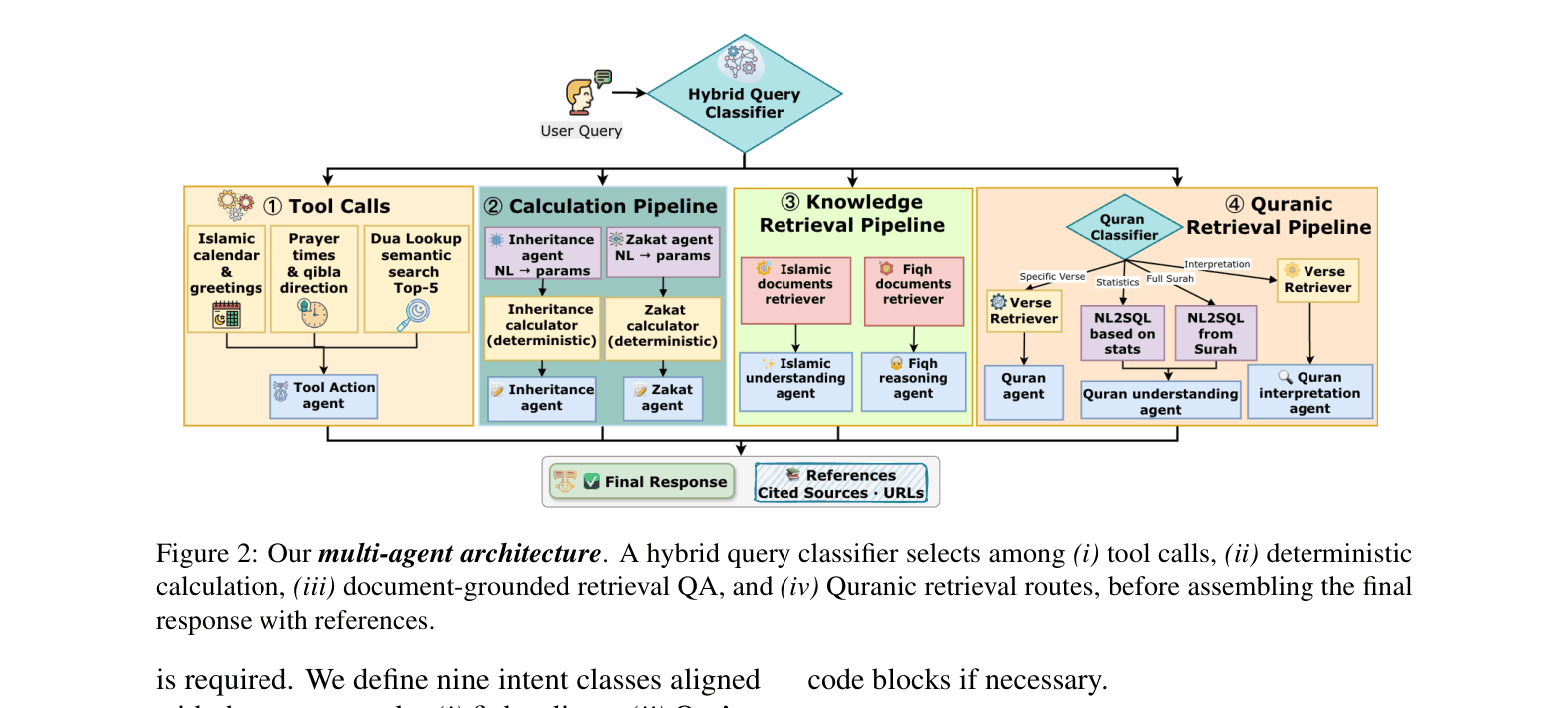
The multi-agent system architecture showing the routing logic and specialized tool execution paths.
Evaluation Highlights
- +17.2% accuracy improvement on the IslamicFaithQA benchmark compared to the base Fanar-2-27B model, demonstrating the value of the agentic architecture
- Achieves 85.5% accuracy on PalmX (Islamic Culture), outperforming GPT-5 (82.3%) and Gemini-3-Pro (84.4%)
- Surpasses GPT-5 on the FatwaQA generative benchmark (65.1% vs 63.6%) by leveraging specialized retrieval and citation grounding
Breakthrough Assessment
8/10
Strong practical contribution demonstrating that domain-specific routing and deterministic tools significantly outperform generalist LLMs on high-stakes religious tasks.