📝 Paper Summary
User-profile based personalization
Memory internalization
Model Editing
The paper reframes personalization as a model editing task using clustered preference representations to enable precise, persistent updates that handle implicit queries without catastrophic forgetting.
Core Problem
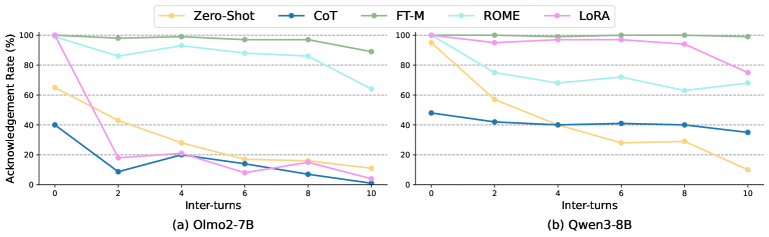
Current personalization methods (fine-tuning, RAG/prompting) are computationally expensive, prone to catastrophic forgetting, or degrade in multi-turn conversations where long contexts dilute preference signals.
Why it matters:
- Prompt-based methods become unreliable in long conversations as relevant information gets lost in the context window
- Fine-tuning is resource-intensive and often causes the model to forget general knowledge or other user preferences
- Existing benchmarks focus on synthetic personas or style imitation rather than the accurate recall of user-specific facts in realistic QA scenarios
Concrete Example:
If a user has a shellfish allergy, a prompt-based model might correctly avoid shellfish initially but later recommend 'crawfish étouffée' after a long conversation dilutes the context. An edited model permanently alters its internal parameters to consistently refuse shellfish.
Key Novelty
Personalization Editing with Clustering-Based Representations
- Conceptualizes user preferences as specific knowledge tuples (Subject, Relation, Object) and uses model editing to inject them directly into weights, ensuring persistence
- Represent preferences not as single facts but as clusters of semantically similar subjects and responses, enabling the model to generalize to paraphrased or implicit queries (e.g., inferring 'hiking' preference from 'weekend activity')
Architecture
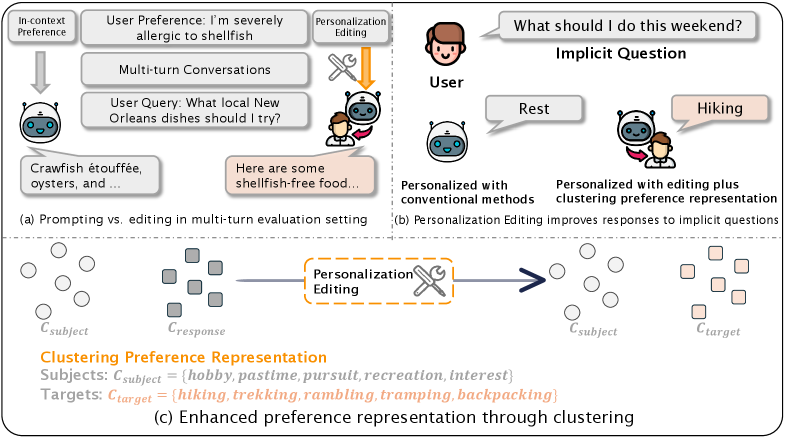
Conceptual comparison between In-Context Learning and Personalization Editing for handling user preferences in multi-turn dialogs and implicit queries.
Evaluation Highlights
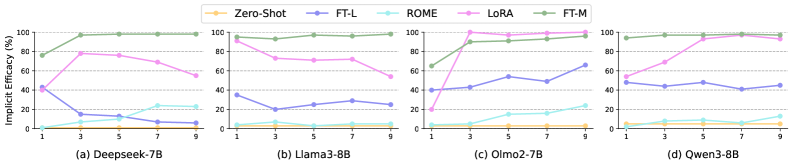
- Outperforms ROME and Zero-shot prompting on implicit questions by >20% efficacy when using cluster size 3
- Maintains >90% Acknowledgment Rate across 10 conversational turns on PREFEVAL, while prompting baselines drop below 20% by turn 8
- Achieves higher editing efficacy than FT-L and FT-M across multiple model families (Llama-3, Mistral) on the UPQA benchmark
Breakthrough Assessment
7/10
Novel application of model editing to personalization with a practical solution (clustering) for the brittleness of standard editing. Strong results on persistence, though primarily an adaptation of existing editing techniques.