📝 Paper Summary
Self-evolving Agentic reasoning
Memory organization
RetroAgent enables RL agents to evolve continuously by generating retrospective intrinsic rewards for exploration and storing textual lessons in a utility-aware memory for future exploitation.
Core Problem
Standard RL optimizes agents for one-off task success via extrinsic rewards, causing them to over-exploit suboptimal policies and fail to reuse accumulated experience effectively.
Why it matters:
- Agents often converge to suboptimal local optima because training stops once a single valid path is found, hindering diverse exploration
- Experience is implicitly buried in model parameters rather than being explicitly retrievable, making it difficult for agents to recall relevant past lessons
- Current methods treat problem-solving as isolated episodes rather than a continuous evolutionary process of adaptation
Concrete Example:
In an embodied task like searching for an item, a standard agent might repeatedly try a purchase action that fails. Without retrospective memory, it forgets the specific reason for the failure (e.g., 'item not found') in the next episode and repeats the mistake, whereas RetroAgent would retrieve a lesson to 'locate the target item before attempting purchase'.
Key Novelty
Retrospective Dual Intrinsic Feedback & SimUtil-UCB Retrieval
- Hindsight Self-Reflection: After an episode, the agent analyzes its trajectory to generate a numerical score (rewarding incremental progress) and a text lesson (for memory)
- Dual Feedback Loop: The numerical score shapes the RL reward to encourage exploration, while the text lesson is stored and retrieved to guide future actions
- SimUtil-UCB: A retrieval strategy that selects memories based on semantic similarity, historical utility (how much they helped before), and exploration (UCB) to avoid stagnating on a few fixed lessons
Architecture
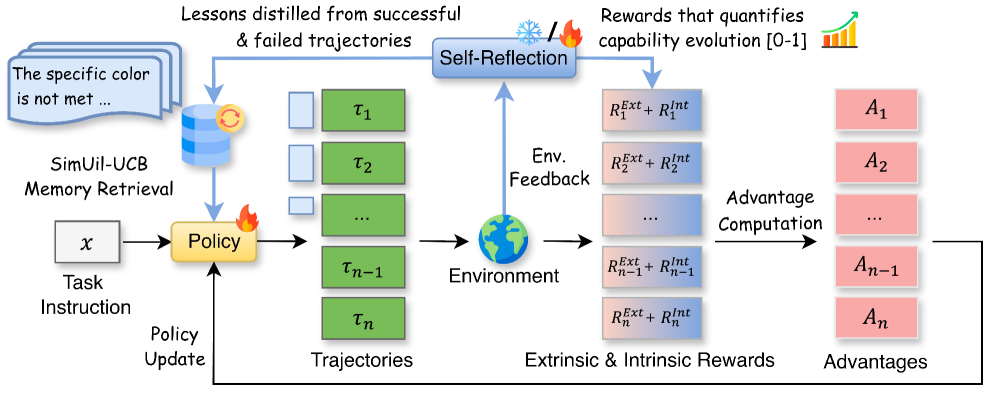
The RetroAgent framework, illustrating the cycle of trajectory generation, hindsight self-reflection, memory update, and policy optimization.
Evaluation Highlights
- Achieves +18.3% improvement over Group Relative Policy Optimization (GRPO) on ALFWorld benchmark
- Surpasses GRPO by +27.1% on Sokoban and +15.4% on WebShop, demonstrating strong capabilities in both reasoning and decision-making tasks
- Outperforms SOTA methods including RL fine-tuning, memory-augmented RL, and meta-RL across four diverse agentic benchmarks
Breakthrough Assessment
8/10
Strong conceptual advance by integrating intrinsic motivation directly with memory retrieval in an RL loop. Significant empirical gains across multiple distinct benchmarks.