📝 Paper Summary
Text-to-Image Generation
Multimodal Reasoning
Chain-of-Thought (CoT)
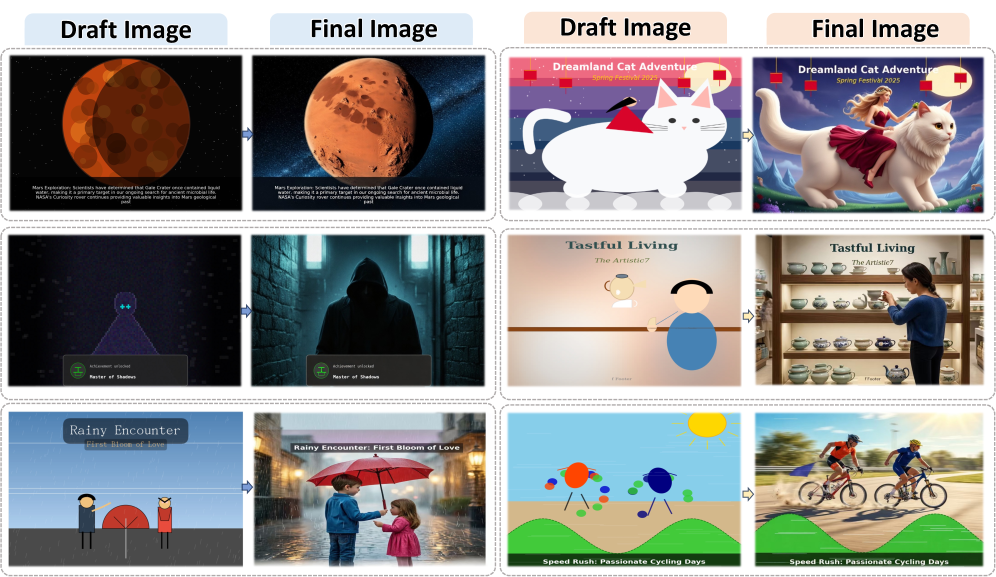
CoCo improves structured image generation by first generating executable code to render a precise draft image, which then guides a unified multimodal model to produce a high-fidelity final output.
Core Problem
Existing text-to-image models rely on abstract natural language planning, which lacks the precision required for complex spatial layouts, scientific diagrams, and dense textual content.
Why it matters:
- Natural language is too abstract to strictly define coordinate systems, geometric constraints, or exact text placement needed for charts and plots
- Current models frequently produce hallucinations or illegible text when creating scientific figures (e.g., mathematical plots) due to a lack of explicit visual grounding
Concrete Example:
When prompted to generate a '2D plot of y=x^2', standard models often produce incorrect curves or gibberish axis labels. CoCo generates Python code to plot the exact function, renders a correct draft, and refines it into a polished image.
Key Novelty
Code-as-CoT (Executable Reasoning)
- Replaces abstract textual 'thoughts' with executable Python code, which deterministically encodes spatial layouts and structural constraints
- Uses the code execution result (a 'Draft Image') as an explicit visual scaffold, allowing the model to 'see' its plan before refining it into a high-fidelity image
Architecture
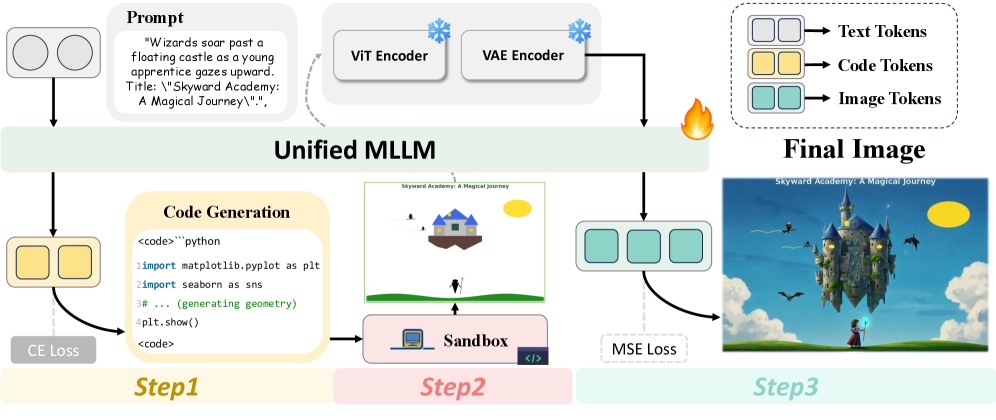
The overall inference pipeline of CoCo, showing the progression from text to code to draft to final image.
Evaluation Highlights
- +68.83% improvement on StructT2IBench compared to the Bagel baseline (direct generation)
- +54.8% improvement on OneIG-Bench compared to Bagel, showing better generalization on multilingual and stylized tasks
- Outperforms text-based Chain-of-Thought approaches by 64.48% on StructT2IBench, validating that code is a superior reasoning medium for structure
Breakthrough Assessment
8/10
Significant conceptual shift from text-based planning to executable code-based planning for generation. Addresses a critical weakness (spatial/structural precision) in current diffusion models.