📝 Paper Summary
Split Federated Learning (SFL)
Hierarchical Federated Learning
The paper proposes an accuracy-aware hierarchical Split Federated Learning algorithm that jointly optimizes model partitioning layers and client-to-aggregator assignments to minimize training delay while maintaining high model accuracy.
Core Problem
Existing Hierarchical Split Federated Learning (HSFL) schemes overlook how the selection of partitioning layers and client-to-aggregator assignments impacts model accuracy, often leading to suboptimal performance.
Why it matters:
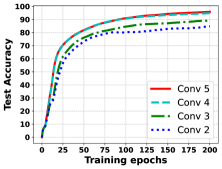
- Selecting a suboptimal cut layer can severely degrade accuracy (as shown with AlexNet/VGG-11), contradicting common assumptions that accuracy is invariant to partitioning.
- Split Federated Learning suffers from high training delays due to backward locking (clients waiting for server) and straggler effects (fast clients waiting for slow ones).
- Current approaches optimize delay or overhead but fail to jointly address the trade-off between minimizing delay and preserving accuracy in a hierarchical setting.
Concrete Example:
In a standard SFL setup with AlexNet, selecting convolution layer 2 as the cut layer results in significantly lower accuracy compared to layer 5. Existing delay-minimizing algorithms might select layer 2 to save bandwidth, inadvertently crippling model performance.
Key Novelty
Accuracy-Aware Hierarchical Split Federated Learning with Local Loss (AA-HSFL-ll)
- Formulates a joint optimization problem that simultaneously selects two partitioning layers (aggregator layer and cut layer) and assigns clients to local aggregators.
- Introduces an accuracy-aware heuristic that first identifies candidate cut layers satisfying an accuracy threshold, then optimizes assignments within that subset to minimize round delay.
- Combines local-loss learning (to mitigate backward locking) with hierarchical aggregation (to mitigate stragglers) in a unified framework.
Architecture
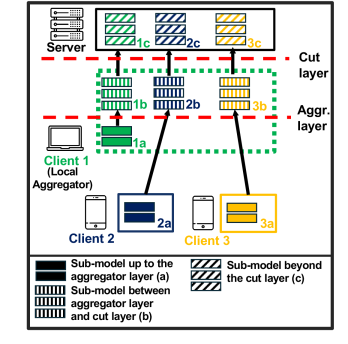
The 3-tier Hierarchical SFL architecture illustrating the partitioning of the model into Weak-side, Aggregator-side, and Server-side sub-models.
Evaluation Highlights
- Improves accuracy by 3% compared to state-of-the-art SFL and HSFL schemes.
- Reduces training delay by 20% and communication overhead by 50% relative to baselines.
- Achieves near-optimal performance compared to exhaustive search while maintaining low computational complexity.
Breakthrough Assessment
7/10
Solid contribution to SFL by rigorously formulating the joint optimization of topology and partitioning. The empirical gain of 3% accuracy + 20% delay reduction is significant for distributed edge learning.