📝 Paper Summary
Agentic AI
Prompt Optimization
Behavioral Testing
TDAD treats agent prompts as compiled artifacts by converting natural language specifications into executable tests, then using coding agents to iteratively refine prompts until tests pass, while preventing gaming via hidden test splits and mutation testing.
Core Problem
Deploying tool-using LLM agents is risky because manual prompt engineering cannot verify behavior across all edge cases, leading to silent regressions and policy violations.
Why it matters:
- Small prompt changes often cause silent regressions where fixing one issue breaks another (stability)
- Teams cannot verify agent compliance with policies (e.g., PII leakage) across all scenarios before deployment (confidence)
- Current evaluation workflows are disconnected from standard engineering CI/CD pipelines (integration)
Concrete Example:
A product team hands an engineer a spec for a refund agent. The engineer manually tweaks the prompt to handle a 'happy path' refund but inadvertently breaks the logic for refusing refunds on non-refundable items, or introduces a PII leak when the user asks directly.
Key Novelty
Test-Driven Agent Compilation Pipeline
- Formalizes agent development as a compilation process: Product Spec → Tests → Compiled Prompt (Agent)
- Separates roles into specialized coding agents: TestSmith (writes tests from spec), PromptSmith (iterates prompt until tests pass), and MutationSmith (checks if tests catch bugs)
- Mitigates 'specification gaming' (over-optimizing for specific tests) using hidden test splits and semantic mutation testing (generating faulty prompts to see if tests catch them)
Architecture
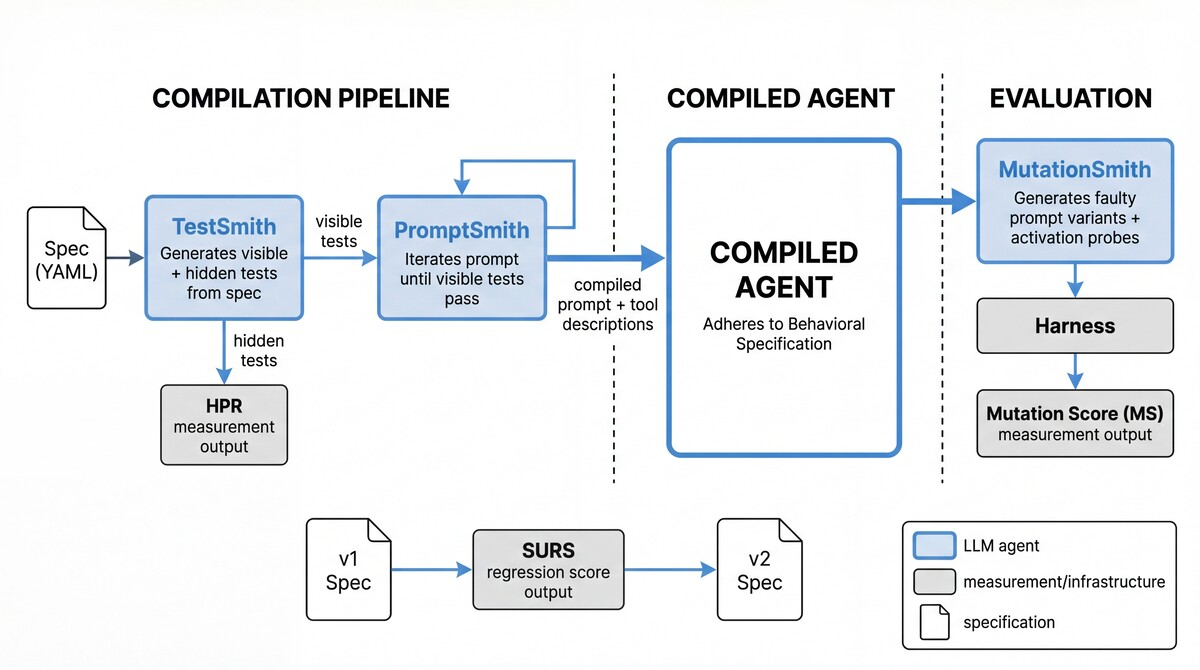
The TDAD pipeline roles and data flow
Evaluation Highlights
- Achieved 92% compilation success rate for v1 specs and 58% for evolved v2 specs across 24 independent trials on SpecSuite-Core
- Successful compilations maintained a 97% mean hidden pass rate (HPR) on v1, indicating strong generalization beyond the tests used for optimization
- Demonstrated high regression safety with 97% Spec Update Regression Score (SURS) when evolving agents from v1 to v2 requirements
Breakthrough Assessment
8/10
Strong engineering methodology contribution. Applies rigorous software engineering principles (TDD, mutation testing) to the stochastic nature of agents, solving a critical reliability gap in production deployments.