📝 Paper Summary
Neuro-symbolic planning
Multi-robot coordination
Scale-Plan improves planning scalability by using a pre-computed action graph to filter irrelevant objects and actions from the environment before using an LLM to decompose and allocate tasks.
Core Problem
Long-horizon planning in object-rich environments fails because irrelevant objects bloat the search space and cause LLMs to hallucinate or produce malformed PDDL problem files.
Why it matters:
- In cluttered households, most sensory data (e.g., a tomato when the task is 'switch off light') is irrelevant, yet traditional planners ingest everything, causing combinatorial explosion
- Pure LLM planners struggle with context limits and grounding, while hybrid approaches like LLM+P often fail to generate valid PDDL files when the scene description is noisy or overly detailed
Concrete Example:
In a task to 'place the apple in the fridge and turn off the light,' standard approaches might include irrelevant objects like pots or dustbins in the problem definition. This causes the planner to explore useless interactions or the LLM to hallucinate constraints for the dustbin, leading to planning failure.
Key Novelty
Domain-Level Action Graph Filtering
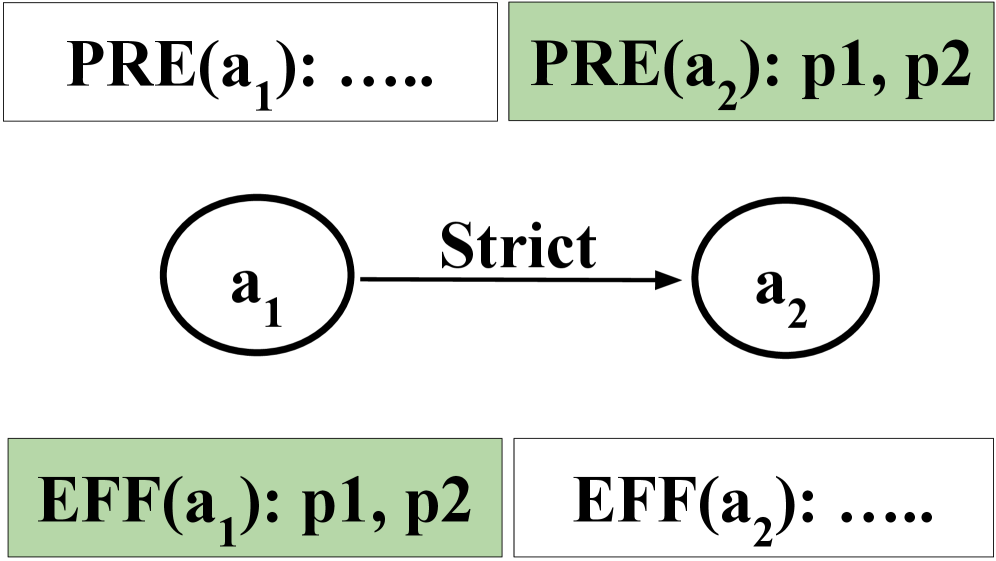
- Constructs a static directed graph of actions from the PDDL domain offline, where edges represent predicate dependencies (one action enables another)
- At runtime, uses shallow LLM reasoning to identify goal actions, then performs a backward graph search to select ONLY the predecessor actions and objects strictly necessary for the task
- Feeds this minimized, task-relevant sub-domain to the planning LLM, bypassing the need for full environment grounding or explicit PDDL problem file generation
Architecture
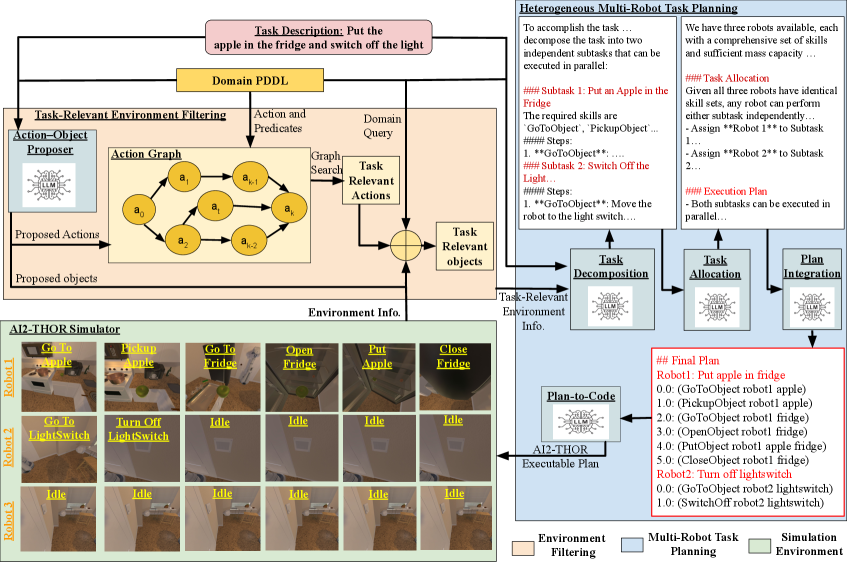
The overall architecture of Scale-Plan, divided into Offline and Runtime phases.
Evaluation Highlights
- Outperforms strongest baseline (LaMMA-P LLM-corrected) by 25% in Task Completion Rate (TCR) overall on the MAT2-THOR benchmark
- Achieves +35% improvement in TCR on 'Complex' tasks compared to LaMMA-P (LLM-corrected), demonstrating superior scalability in long-horizon scenarios
- Maintains 9% higher Executability Rate (ER) than baselines, indicating generated plans are more robust to low-level simulator failures
Breakthrough Assessment
8/10
Significant improvement in handling cluttered environments for multi-robot systems by solving the 'irrelevant context' problem via structured graph search. The removal of intermediate PDDL generation for the problem file is a strong design choice.