📝 Paper Summary
Synthetic Data for LLM Pre-training
Pre-pre-training strategies
Pre-pre-training language models on synthetic data generated by Neural Cellular Automata (NCA) instills transferable computational priors that improve downstream performance and convergence on natural language tasks.
Core Problem
Natural language data is finite, biased, and entangles reasoning with knowledge, making it difficult to isolate and train pure reasoning capabilities efficiently.
Why it matters:
- High-quality natural text data may be exhausted by 2028 according to scaling laws
- Natural language corpora require expensive curation and contain undesirable human biases
- Current synthetic data approaches (random strings, simple grammars) often fail to match the performance of natural language training under matched budgets
Concrete Example:
Training on random strings or simple formal languages (like Dyck-k) often yields poor transfer to real language tasks because these distributions lack the rich, long-range spatiotemporal structures found in natural text.
Key Novelty
NCA Pre-pre-training
- Use Neural Cellular Automata (NCA) to generate synthetic, non-linguistic token sequences that exhibit rich, controllable spatiotemporal patterns and Zipfian statistics
- Train models on this synthetic data first (pre-pre-training) to learn general computational primitives like rule inference and long-range dependency tracking before seeing any natural language
- Filter NCA rules by gzip compression ratio to tune data complexity for specific downstream domains (e.g., lower complexity for code, higher for math)
Architecture
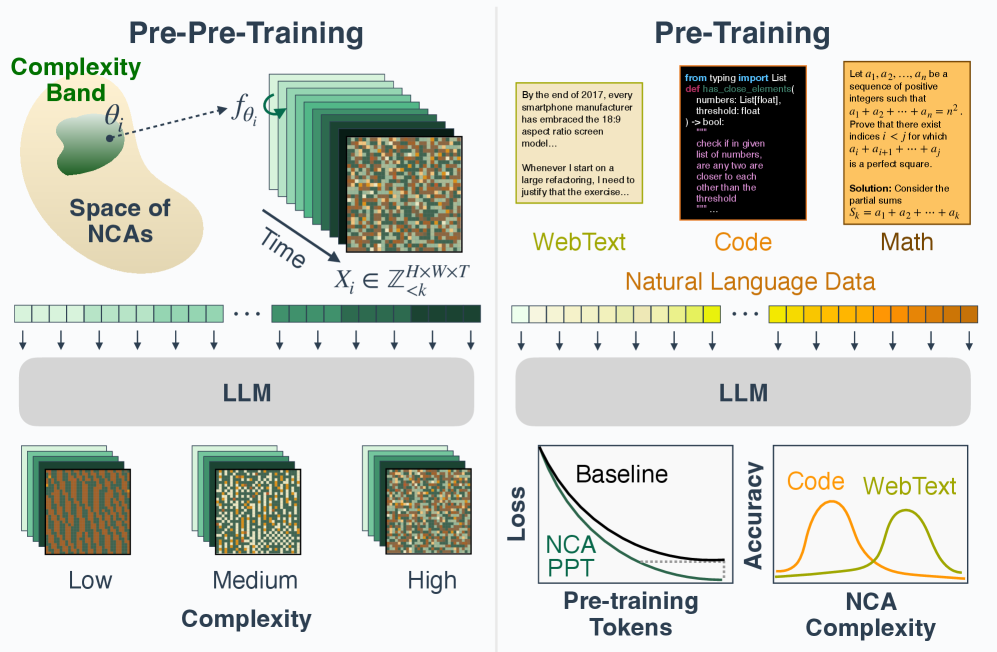
Visualization of NCA rollouts with varying complexity levels, alongside their gzip compression ratios.
Evaluation Highlights
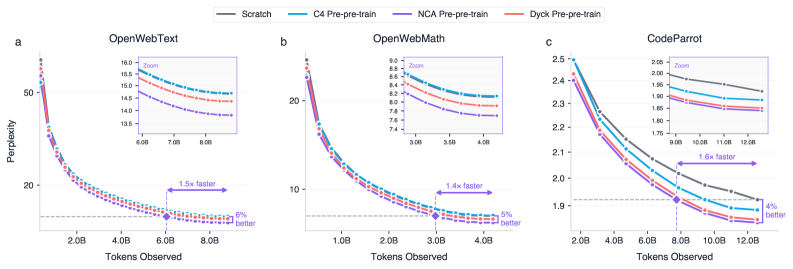
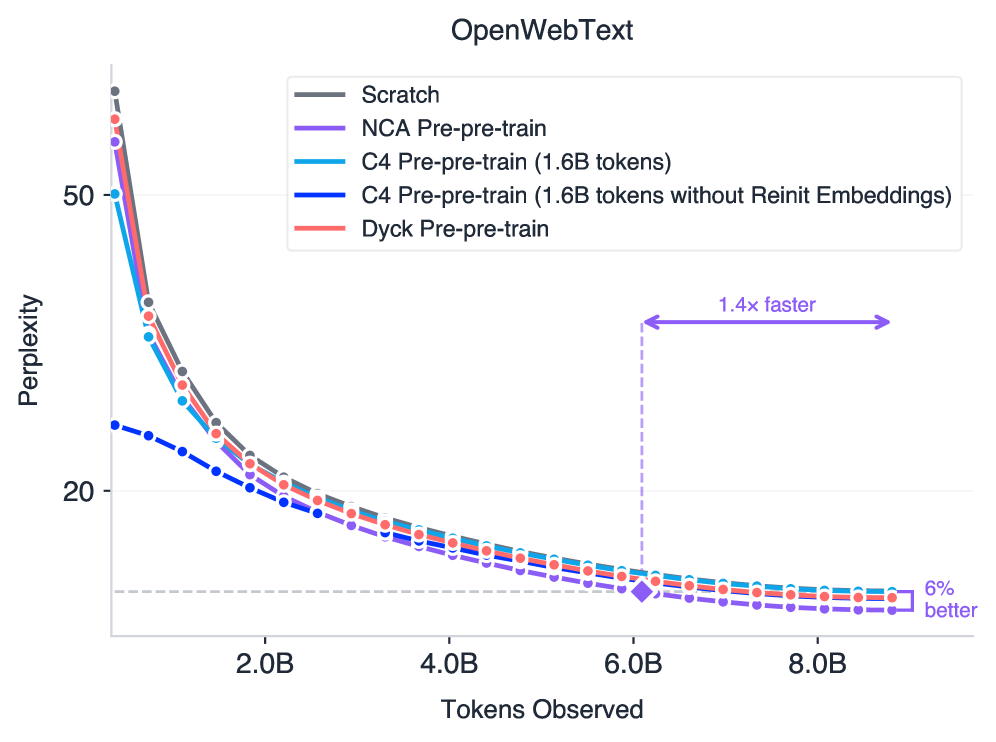
- Improves downstream perplexity on OpenWebText by up to 5.7% (1.6B model) compared to training from scratch
- Accelerates convergence by up to 1.6× on web text, math, and code datasets compared to scratch baselines
- Outperforms pre-pre-training on natural language (C4) by 5% perplexity even when the C4 baseline uses 10× more data (1.6B vs 160M tokens)
Breakthrough Assessment
8/10
Demonstrates that non-linguistic synthetic data can outperform natural language for acquiring core computational priors, offering a path to bypass data scarcity limits. The 10x data efficiency vs C4 is particularly significant.