📝 Paper Summary
Federated Learning (FL)
Edge Intelligence
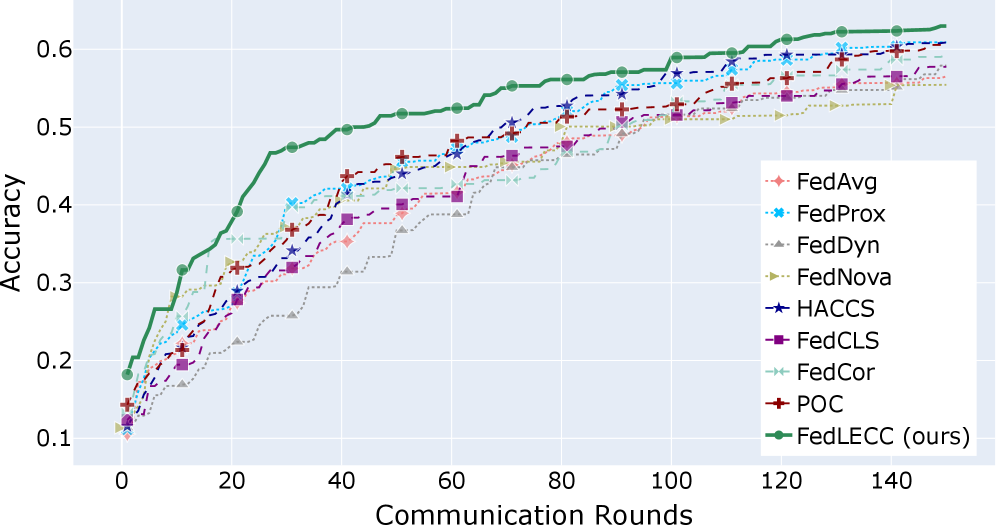
FedLECC improves federated learning under non-IID data by clustering clients based on label distributions and prioritizing those with high local loss to select informative yet diverse updates.
Core Problem
In cross-device FL, non-IID data (specifically label skew) causes client updates to diverge, degrading model convergence and accuracy, especially when random client selection is used.
Why it matters:
- Label skew is common in cloud-edge deployments where clients capture localized events or user-specific behaviors.
- Naive selection strategies waste communication resources on redundant or low-impact updates, slowing convergence.
- Uniform sampling is suboptimal in heterogeneous environments where only a small fraction of clients can participate due to bandwidth constraints.
Concrete Example:
Consider a predictive maintenance scenario where different edge devices monitor different machine types (disjoint labels). Randomly selecting clients might repeatedly sample devices with 'Machine Type A' data while ignoring 'Machine Type B', leading to a global model that fails to detect faults in Type B.
Key Novelty
Cluster-Aware Loss-Guided Selection
- Groups clients into clusters using Hellinger distance between their label distributions to identify devices with similar data characteristics.
- Selects clients by first choosing clusters with high average loss, then picking specific clients within those clusters with the highest local loss.
- Jointly enforces diversity (via clustering) and informativeness (via loss prioritization) to prevent over-specialization to specific data modes.
Architecture
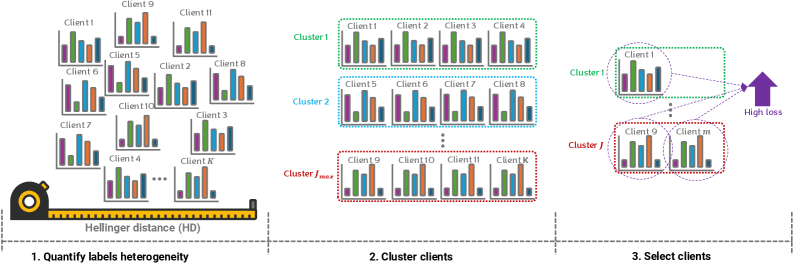
Conceptual overview of the FedLECC strategy stages.
Evaluation Highlights
- +12% test accuracy improvement on FMNIST under severe label skew compared to FedAvg and strong baselines.
- Reduces communication rounds by approximately 22% to reach target accuracy compared to FedAvg.
- Reduces overall communication overhead by up to 50% compared to strong baselines like FedCor and POC.
Breakthrough Assessment
7/10
Solid systems contribution for FL. Effectively combines two known heuristics (clustering and loss-based selection) to address the specific problem of label skew, showing significant efficiency gains.